



摘要
在超大规模分布式存储系统的演进过程中,如何将海量数据从异构的第三方云存储平滑、安全、零停机地迁移至自研平台,是衡量存储团队技术实力的试金石。本文详细解构了京东 ChubaoFS 团队如何通过自研S3 数据迁移平台,采用“增量旁路监听+存量高并发搬运+双重兜底校验”的组合策略,成功助力达达业务完成54 亿文件、800TB数据的无缝迁移,实现了在业务不停写、用户无感知前提下的底层存储架构“热切换”。
第一章 项目背景与技术挑战
1.1 ChubaoFS:京东零售统一存储底座
ChubaoFS是京东自主研发的云原生分布式文件系统,也是京东零售技术体系内的统一存储资源池。在零售内部服务了众多的核心业务,
- 全场景覆盖:ChubaoFS 不仅服务于公司内部广告、搜索、推荐、点击流分析、军演压测、AI 大模型训练等众多核心在线业务,也作为坚实的底层底座,支撑了 JED、JMQ、JDQ、Logbook、JES、HBase、ClickHouse 等中间件产品的存算分离架构演进 。
- 多协议互通:ChubaoFS 实现了对 POSIX、S3、HDFS 等多种主流接口的完美支持,并且实现了“一份数据,多协议可见”。这意味着用户通过 S3 接口写入的对象,可以直接在 POSIX 挂载点被访问,极大地消除了数据孤岛 。
1.2 达达业务的存储痛点与诉求
在全面融入京东技术生态之前,达达业务的数据长期分散存储于七牛云的 KODO 和又拍云的 USS 等第三方对象存储服务中 。随着业务规模的指数级增长,原有的异构存储架构逐渐暴露出一系列问题:
- 成本压力:公有云存储成本随着数据量的激增而线性上升。
- 运维复杂性:多云管理带来了割裂的运维体验和潜在的一致性风险。
- 扩展性瓶颈:难以复用京东内部成熟的存算分离技术栈。
为了追求极致的成本控制、更高的存取效率,以及系统的高可用性(HA)和高性能,达达决定将存储服务全面迁移至 ChubaoFS 。
1.3 “给飞行中的飞机换引擎”
此次迁移面临着较高的技术门槛。迁入 ChubaoFS 的业务基本都属于在线核心业务,在迁移的全过程中,旧的存储服务一刻也不能停写。这无异于在万米高空给正在飞行的飞机更换引擎——既要保证万米高空(线上业务)的平稳运行,又要完成引擎(存储底层)的无缝切换。为了完成这一艰巨任务,并为后续更多外部业务接入沉淀通用能力,我们开发了S3 数据迁入平台,利用 ChubaoFS 的 S3 功能实现业务无感知的平滑接入 。
第二章 核心迁移策略与架构演进
针对“在线不停机”的极端场景,传统的离线迁移或停机割接方案已不再适用。为了保证数据的强一致性,S3 数据迁入平台包含两个核心阶段(存量与增量)与两个兜底阶段(校验与回源)的四步走策略。
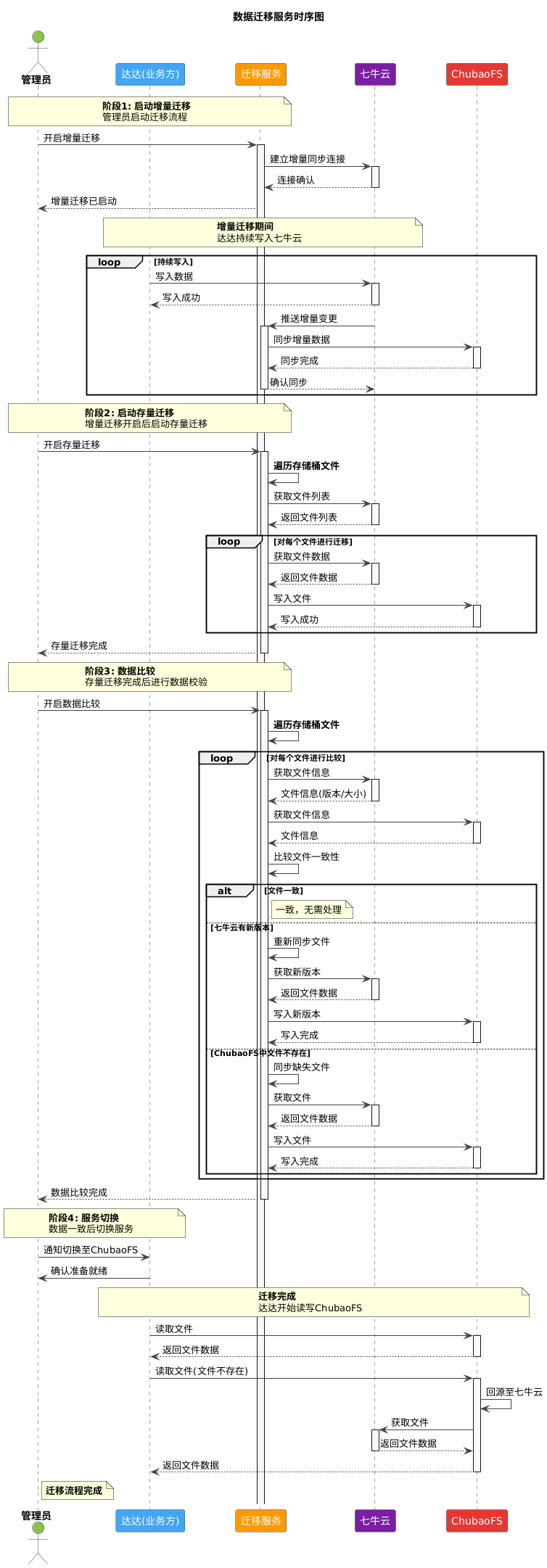
2.1 总体战略:存量与增量协同并进
针对不停写的业务场景,迁移过程被划分为两个核心战场:
- 存量迁移阶段:负责将某个时间点(Snapshot)之前的历史存量数据,通过高并发扫描同步至目标新服务 。
- 增量迁移阶段:负责同步存量迁移期间,以及迁移完成后业务新产生的数据 。
这两个阶段并非简单的串行关系,而是需要协同推进。其核心目标是消除新旧存储的数据差异,保障迁移过程中数据的实时一致性 。
2.2 阶段一:增量迁移(建立旁路事件管道)
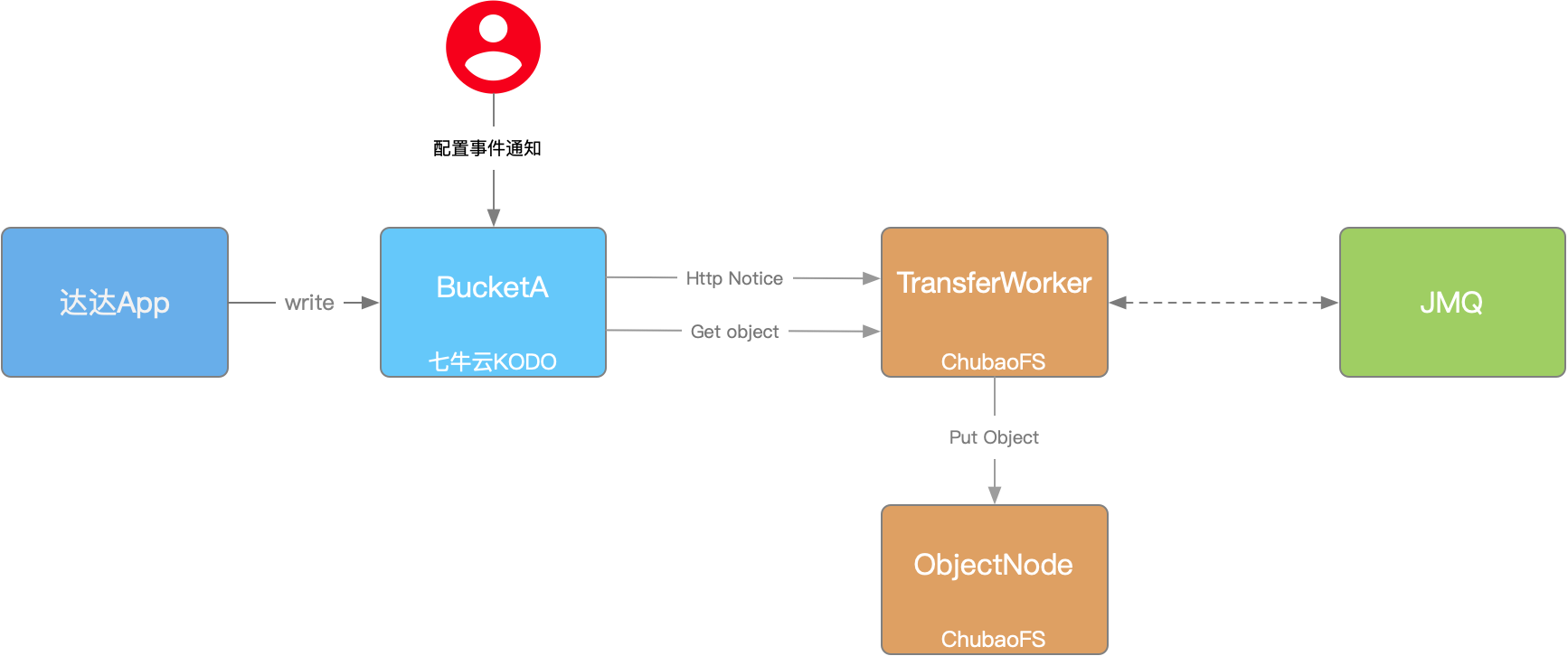
在启动全量搬运之前,必须先切断数据增量的“水位”。我们利用对象存储服务(如七牛云 KODO)提供的事件通知功能,建立了一条旁路数据管道 。
- 监听机制:在源端存储桶(Bucket)上配置监听规则,涵盖文件创建、修改、删除等特定操作 。
- 消息驱动:当业务在旧存储发生写操作时,云厂商系统会将生成的事件通过消息队列或 API 接口实时推送给我们的迁移服务,从而触发增量数据同步 。
- 异构存储事件的语义映射:S3 迁移服务聚焦于对 Bucket 内文件的写操作。由于不同存储系统的实现差异,我们需要建立严格的语义映射表 :
| 七牛事件类型 | 语义描述 | ChubaoFS 迁移行为决策 | 技术考量 |
| put / mkfile | 上传新文件/分片完成 | 写新文件 | 标准对象上传行为。 |
| copy | 复制文件 | 在目标 Bucket 写新文件 | 跨 Bucket 的资源复制。 |
| move | 移动文件 | 目标写新文件 + 源删除 | S3 协议本身无原子 Rename,需拆分为 Copy+Delete。 |
| delete | 删除文件 | 删除文件 | 保持目标端数据及时清理。 |
| append | 追加写 | 重新写新文件 | ChubaoFS S3 服务暂不支持 Append 操作,因此采用全量覆盖写策略以保证数据最终一致性。 |
S3 迁移服务在收到通知后,会立即执行上述操作,确保增量数据实时同步至 ChubaoFS 或从 ChubaoFS 删除 。
2.3 阶段二:存量迁移(全量并行搬运)
当增量通道稳定运行后,我们启动存量数据的搬运。设计原则如下 :
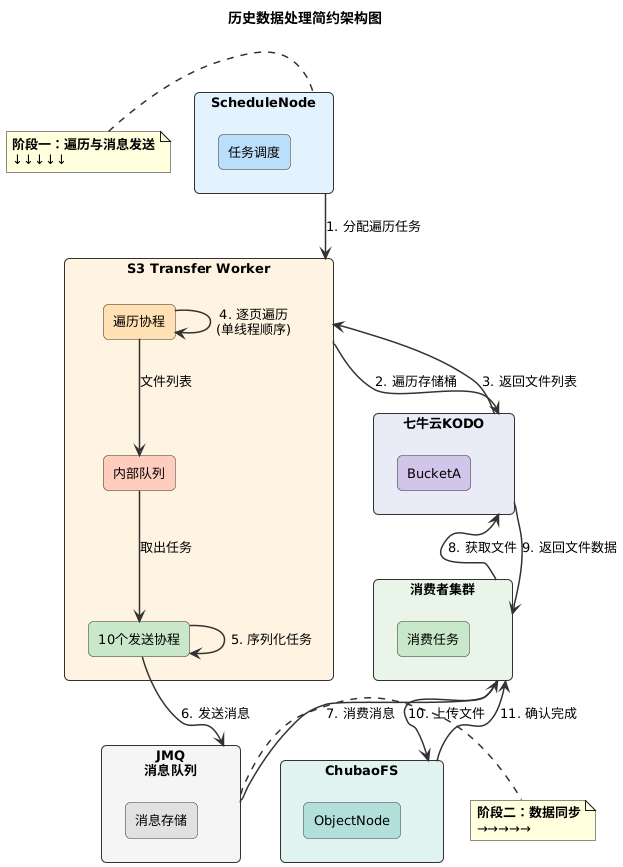
- Bucket 级隔离:以存储桶为维度进行任务拆分,每个 Bucket 创建独立迁移任务,不同 Bucket 间并行迁移,互不干扰,最大化利用带宽 。
- 任务管理架构:基于 ChubaoFS 现有的
ScheduleNode调度框架构建 。 - ScheduleNode:负责统一调度与管理。
- S3 Transfer Worker:扩展出的新模块,负责具体的搬运执行,实现了管理与执行的解耦。
为了实现数据的可靠性,我们设计了多重熔断与兜底机制 :
- 断点续传机制:迁移过程定时记录进度。一旦节点发生故障或重启,Worker 可从上次记录的断点继续迁移,不会从头开始 。
- 完整性校验:迁移完成后进行数据一致性比对 。
- 状态追踪:全量记录任务指标 。
2.4 阶段三:数据比较(Consistency Check)
迁移完成后,系统通过遍历方式(listObjects)获取源端文件列表,逐个调用七牛云和 ChubaoFS 的getObjectMeta接口。通过比对Size、eTag等核心元数据,精确判断两侧文件是否一致 。
2.5 阶段四:回源访问(Lazy Migration)
为了防止迁移过程中出现数据缺失,ChubaoFS 增加了回源访问功能,在业务将服务迁移到ChubaoFS之后,通过ChubaoFS访问文件时,如果出现了404(Not Found),对于存在映射关系的bucket,ChubaoFS会根据映射关系回源旧存储服务,如果文件在旧服务存在会自动同步至ChubaoFS,进一步提高业务服务的高可用性。
第三章 关键技术实现深度剖析
3.1 ScheduleNode 与 Worker 的协同
- ScheduleNode:作为大脑,负责任务生命周期管理。针对 S3 迁移任务,它会调度专门的S3 Transfer Worker节点 。
- S3 Transfer Worker:作为手脚,执行具体的数据搬运逻辑 。
3.2 事件通知回调的高可用设计
七牛云的事件通知仅支持 HTTP 推送。S3 Transfer Worker 对外暴露 HTTP 接口并注册到七牛云 。 为了应对网络抖动和处理积压,我们采用了异步削峰设计:
- 快速接收:接口接收到消息后,不做任何业务处理,直接将消息推送到内部消息队列。
- 异步消费:后端消费者从队列取消息进行处理。
- 重试机制:如果处理失败,利用消息队列的 ACK/NACK 机制触发重试,确保事件不丢失 。
3.3 遍历与同步:生产者-消费者模型深度优化
存量数据的处理是性能瓶颈所在,主要受限于 S3 接口的列举限制。我们将其拆分为两个阶段:
- 遍历阶段:遍历存储桶下所有文件,生成任务消息 。
- 同步阶段:消费消息,执行数据搬运 。
突破单线程遍历瓶颈S3 协议规定,ListObjects必须按照 ObjectKey 字节码顺序逐页返回(每页最多 1000 条)。这意味着遍历必须是单线程、顺序进行的,无法并行。 为了提高遍历和发送消息的速度,S3 Transfer Worker 采用了1:10 的生产者-消费者模型:
- 生产者(1个协程):专注于“快跑”,单线程循环调用 List 接口,将结果塞入内存中的
内部队列。 - 消费者(10个协程):专注于“干活”,从内部队列并发取出任务,序列化后发送到外部消息队列(JMQ)。
这种设计将网络 I/O、序列化开销与遍历逻辑彻底解耦,避免了单协程处理时因发送延迟拖累遍历速度,从而显著提升了整体进度 。
Crash Consistency:偏移量防丢机制Worker 节点随时可能宕机。ScheduleNode 重新调度任务后,新节点必须能接力工作 。 这里存在一个并发竞态风险:如果遍历协程已将文件放入内部队列,但发送协程还没来得及发到 MQ,此时节点宕机,这部分文件就会遗漏。解决方案:每个发送协程在成功发送消息后,才会定时更新共享的偏移量记录。偏移量的更新保证线程安全并定期持久化。如此,新节点启动时,会从“已确认发送”的位置继续遍历,确保不会发生文件的遗漏。
3.4 同步逻辑与带宽优化
S3 Transfer Worker 是无状态的,支持水平扩容。在处理文件同步时,它执行以下逻辑 :
文件不存在场景(全量同步)
- 动作:从源服务下载并写入 ChubaoFS。
- 元数据保留:同步过程中完整保留
content-type、content-disposition、cache-control等 HTTP 头信息,避免文件语义变化 。 - 溯源设计:文件写入 ChubaoFS 后会生成新的 Size/ETag。系统会将源服务的原始属性(Original Size/ETag/LastModified)存储在 ChubaoFS 文件的**扩展属性(X-Attr)中,便于后续追踪和比对 。
文件已存在场景(幂等检查)
- 动作:检查 ChubaoFS 中文件的元数据是否与任务信息一致 。
- 比对逻辑:利用扩展属性中存储的源文件信息进行比对。
- 优化收益:如果信息一致,直接跳过该文件的同步操作。对于重试任务或部分重复任务,这一机制有效节省了昂贵的公网带宽资源 。
第四章 分布式进度管理与高并发控制
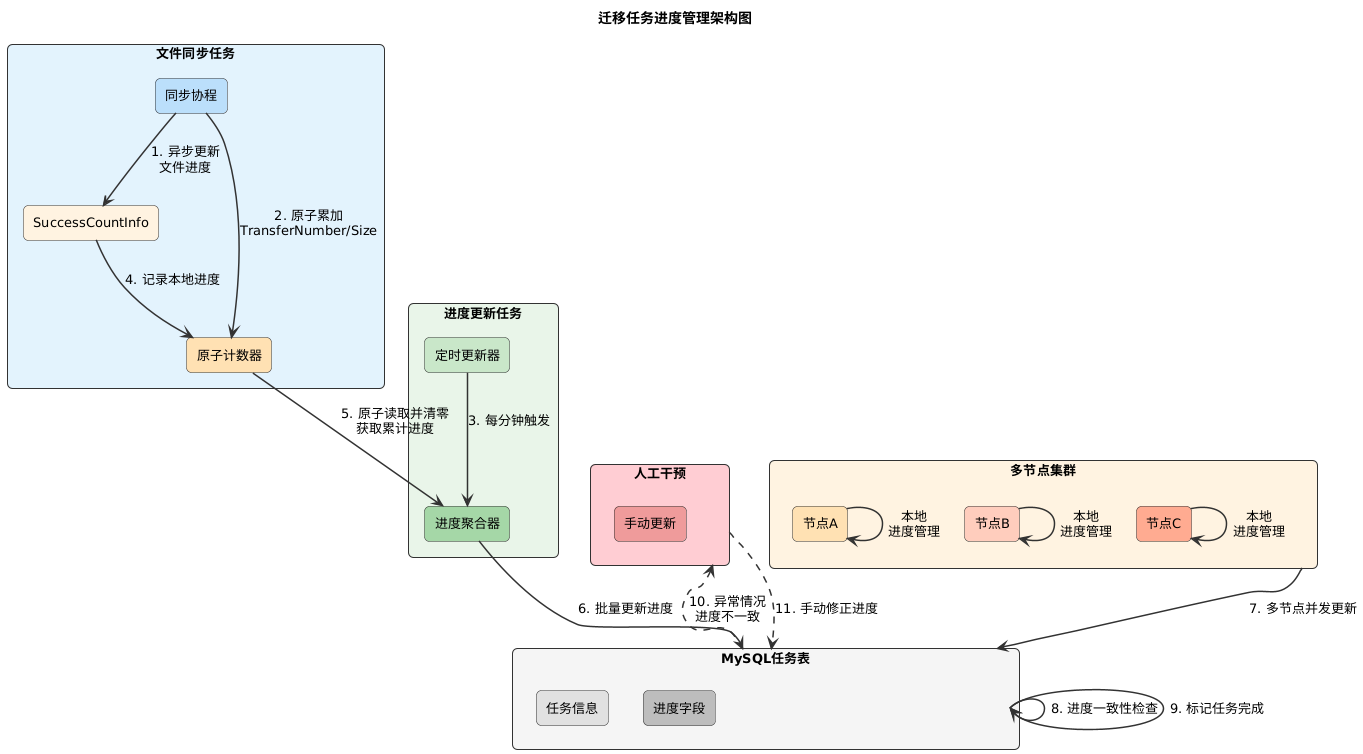
4.1 进度记录:SuccessCountInfo
每个迁移任务在内存中维护一个SuccessCountInfo结构体,用于实时记录进度 :
type SuccessCountInfo struct {
TransferNumber uint64 // 成功迁移文件数量
TransferSize uint64 // 成功迁移数据大小
}
文件同步成功后,系统会异步更新该结构体,确保进度及时反映 。
4.2 分布式进度更新策略
所有任务信息(包括进度)存储在 MySQL 任务表中。为了减轻数据库压力,我们拒绝了“每传一个文件写一次库”的低效做法,而是采用了“内存聚合 + 定时批量落盘”策略 。
4.3 原子操作与乐观锁并发控制
当一个大 Bucket 的任务被分片到多个 Worker 节点并行处理时,数据库更新面临并发覆盖风险。我们设计了严密的并发控制逻辑 :
- 内存原子性:文件同步任务通过原子操作(Atomic Add)累加本地的
TransferNumber和TransferSize。进度更新任务则原子地读取并原子地减去这些累计值,确保两个过程互不影响,数据不重不漏 。 - 数据库乐观锁:在更新 MySQL 时,各节点使用带条件的更新语句:
UPDATE task_tableSET progress = new_valueWHERE id = task_id AND progress = old_value
节点先查询当前进度,更新时携带该值作为条件。如果更新时发现 DB 中的进度值已变化(说明被其他节点抢先更新),则放弃本次更新,等待下个周期。这一机制完美解决了分布式环境下的状态冲突问题 。
4.4 任务完成判定
系统通过对比“迁移成功总数”与“遍历阶段发现的文件总数”来判定任务是否结束。注:在节点故障等极端情况下,可能导致部分内存中的进度信息丢失。针对这种低概率场景,系统支持人工干预手动修正状态 。
4.5 核心数据结构源码解析
为了便于技术人员理解,以下展示了系统中用于状态管理的核心 Go 语言结构体定义 :
type S3TransferWorker struct {
// key: taskId_srcBucket_destBucket, value: BucketCountInfo
bucketCountInfo sync.Map
// key: taskId_srcBucket_destBucket, value: FailureCountInfo
bucketFailedDetail sync.Map
}
// 成功计数器
type SuccessCountInfo struct {
TransferNumber uint64
TransferSize uint64
}
// 失败详情容器
type FailureCountInfo struct {
Details []*proto.S3TransferDetail
}
// 详细的传输记录
type S3TransferDetail struct {
TaskId uint64
SrcBucket string
DstBucket string
ObjectKey string
CountNum int
ExceptionInfo string
WorkerAddr string
CreateTime time.Time
UpdateTime time.Time
}
第五章 异常熔断与自我保护机制
为了便于监控和排查,系统将异常分为任务级别和文件级别。
- 任务级别异常:记录在任务主表中,跟踪整体状态。
- 文件级别异常:记录在独立的异常明细表中 。
5.1 数据库防爆设计
考虑到单个任务可能涉及数十亿文件,如果发生配置错误(如 AK/SK 错误)导致所有文件迁移失败,直接记录每个文件的异常将导致明细表瞬间膨胀数亿条记录,拖垮数据库。为此,系统实施了以下优化 :
- 批量更新机制:异常信息同样采用定时批量插入,拒绝高频单条写入 。
- 阈值熔断控制:每次更新前,检查当前任务在异常表中的记录数。若超过预设阈值(例如 1000 条),则停止插入新记录。通常前 1000 条错误已足够工程师定位共性故障原因 。
- 循环清理机制:故障修复后,系统支持清空该任务的历史异常记录,重新开始记录后续异常,实现系统的“自愈” 。
这一机制在保证问题可追溯性的同时,极大地降低了系统的存储风险。
第六章 迁移成果与总结
6.1 实战战报
截至目前,ChubaoFS S3 数据迁移平台已在达达业务迁移中取得了里程碑式的成果 :
- 迁移存储桶规模:完成47 个核心业务 Bucket 的迁移。
- 文件处理量级:累计迁移文件数量超54 亿。
- 数据吞吐总量:迁移数据总量逾800 TB。
6.2 价值总结
通过“增量旁路监听”与“存量并行搬运”的结合,以及“数据校验”与“回源访问”的双重兜底,我们成功实现了在业务不停机、用户无感知的情况下,完成了 PB 级数据的底层存储架构升级。有效验证了 ChubaoFS 在大规模异构数据接管场景下的技术成熟度与高可靠性。





