




论文链接:https://arxiv.org/abs/2602.23964(已录用SIGIR2026)
1. 背景:
1.1 生成式检索(GR)的技术范式
在电商搜索领域,“生成式检索”范式逐渐兴起并得到越来越多的关注。生成式检索通过将海量商品(SKU)编码为结构化的语义 ID(Semantic ID, SID),将检索任务转化为一个自回归生成任务 。
SID 的构建原理:通常采用层次化聚类(如 RQ-VAE 或 RQ-Kmeans)构建 。这种“由粗到细”的层级结构使得模型能够通过 Beam Search 在十亿级商品库中实现毫秒级响应
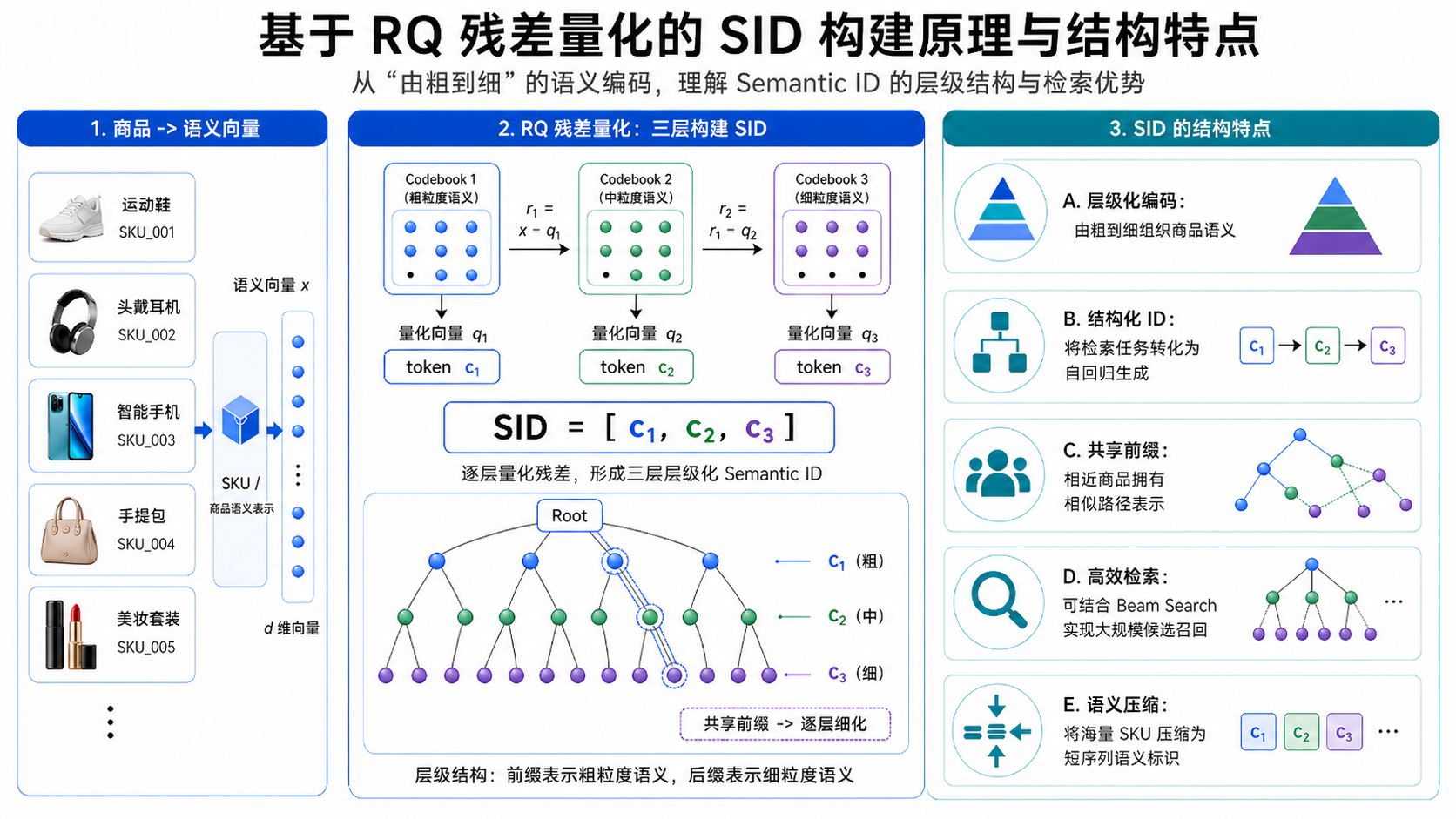
训练阶段:一般分为语义对齐预训练(Pre-train)、个性化对齐指令微调(SFT)和偏好对齐优化(DPO/RL)三个阶段 。
1.2 为什么需要 DPO?
电商环境拥有极其丰富的隐式偏好信号(如曝光、点击、加购、下单) 。传统的精排模型通过交叉熵或序关系损失来吸收这些信号,而 GR 模型在经过 SFT(指令微调)后,仍需进一步对齐用户意图 。相比其他强化学习算法如GRPO、PPO,DPO 的优势在于其不依赖额外的 Reward Model,实现简单且样本获取成本低。
1.3 GR 场景下的特殊挑战
不同于自然语言处理(NLP)任务,生成式检索下的 DPO 具有以下独特性 :
梯度冲突(Shared Prefixes):SID 具有层级性,正负样本常共享类目前缀 。标准 DPO 在惩罚负样本时,会无差别地打压这些正确的前缀路径,导致类目生成的震荡 。
噪声敏感(Pseudo-negatives):电商的“未点击”并不等同于“不相关”,可能是位置偏见导致的 。强行对比这种“伪负例”会扭曲模型的语义表示 。
概率挤压(Squeezing Effect):电商 Query 通常对应多个相关正样本(Multi-label) 。打压负样本(尤其是难负样本和伪负样本)的同时可能会压缩长尾正样本的概率空间 。
2. 算法演进:主流偏好对齐方案对比
我们对现有的DPO类算法进行了调研整理,选取其中的代表性方法总结如下:
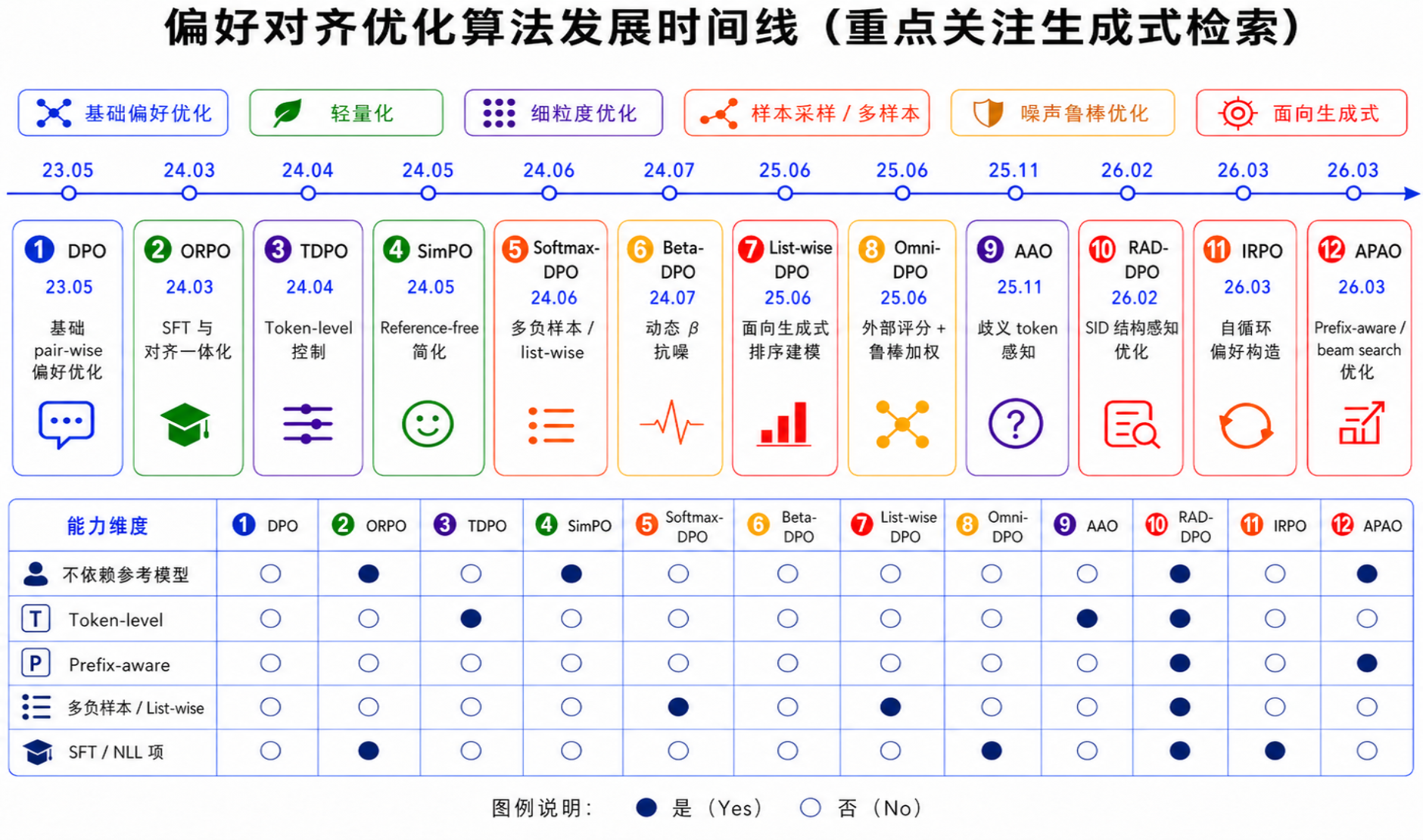
整体趋势可以概括为:
| 演进方向 | 代表方法 | 趋势说明 |
| 轻量化 | SimPO、ORPO | 从依赖参考模型转向 reference-free,减少显存和计算开销 |
| 提升样本利用效率 | Softmax-DPO、IRPO | 从 pair-wise 走向 multi-sample / list-wise,一次利用多个负样本 |
| 增强细粒度控制 | TDPO、AAO | 从序列级奖励转向 token 级建模,减少粗粒度梯度带来的误伤 |
| 提升噪声鲁棒性 | Omni-DPO、Beta-DPO | 通过动态权重、外部评分、动态 β 或离群过滤缓解噪声数据问题 |
| 面向生成式检索结构优化 | list-wise DPO、APAO、 RAD-DPO | 从通用偏好优化进一步走向SID 结构感知、伪负例识别、多目标融合、样本构成优化 |
在生成式检索/推荐后训练对齐领域,逐渐有工作开始针对SID的层次化结构进行token级的细粒度优化,例如APAO和OneSearch-V2提出的TPMA-GRPO,他们采用了不同的策略对SID前缀token做单独建模增强。
一句话总结:DPO 变体的演进主线是从“简单 pair-wise 序列级偏好优化”,逐步走向“低成本、多样本、token 级、噪声鲁棒、prefix-aware 和结构感知”的优化范式;RAD-DPO 的核心定位是把这些趋势进一步落到生成式检索的 SID 结构和伪负例问题上。
3. RAD-DPO 核心技术方案:面向 SID 结构的鲁棒偏好对齐
前面我们分析了标准 DPO 在生成式检索场景下的三个核心问题:公共前缀被误伤、隐式反馈噪声敏感、多正例概率挤压。RAD-DPO 的设计目标,就是把通用的序列级偏好优化,改造成更适合电商 SID 生成的结构化偏好学习方法。
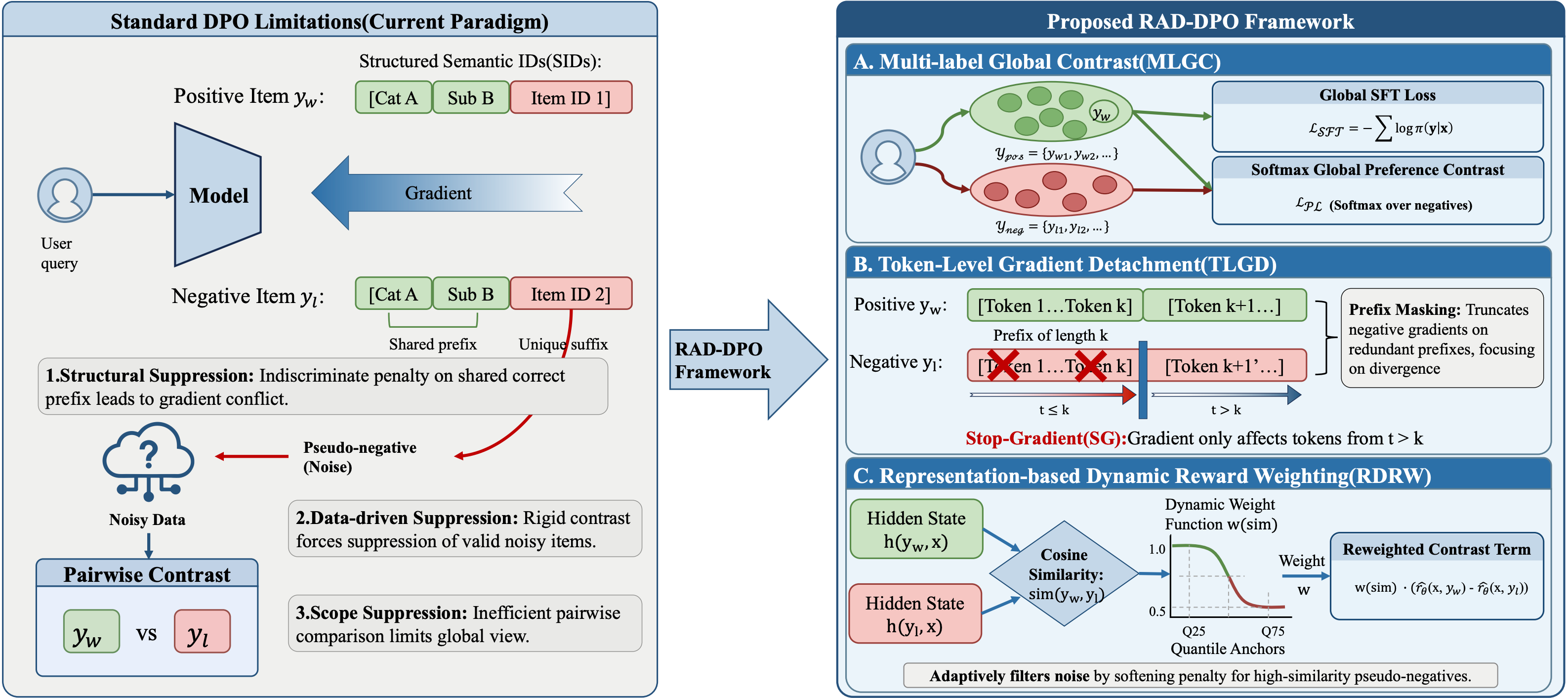
从整体上看,RAD-DPO 由三个相互配合的模块组成:
| 模块 | 解决问题 | 核心思想 |
| MLGC:Multi-label Global Contrast | 多正例概率挤压 | 从 pair-wise 对比扩展到 session 级多标签全局对比 |
| TLGD:Token-Level Gradient Detachment | 公共 SID 前缀被误伤 | 对负样本共享前缀执行 Stop-Gradient,避免正确前缀的梯度被抵消 |
| RDRW:Representation-based Dynamic Reward Weighting | 曝光未点击中的伪负例 | 根据正负样本表示相似度动态降低疑似伪负例惩罚 |
3.1 从 pair-wise DPO 到 session 级偏好学习

3.2 MLGC:多标签全局对比,缓解正样本概率挤压
 3.3 TLGD:Token 级梯度截断,保护 SID 公共前缀
3.3 TLGD:Token 级梯度截断,保护 SID 公共前缀


前向计算时,负样本公共前缀仍然参与 likelihood 计算;反向传播时,切断负样本公共前缀上的梯度,只在正负样本真正分叉的位置之后进行惩罚。

3.4 RDRW:动态奖励加权,降低伪负例误伤

 3.5 三个模块的整体协同
3.5 三个模块的整体协同

 4. 实现细节
4. 实现细节


4.1 Label Packing:把多候选样本压到一次前向中

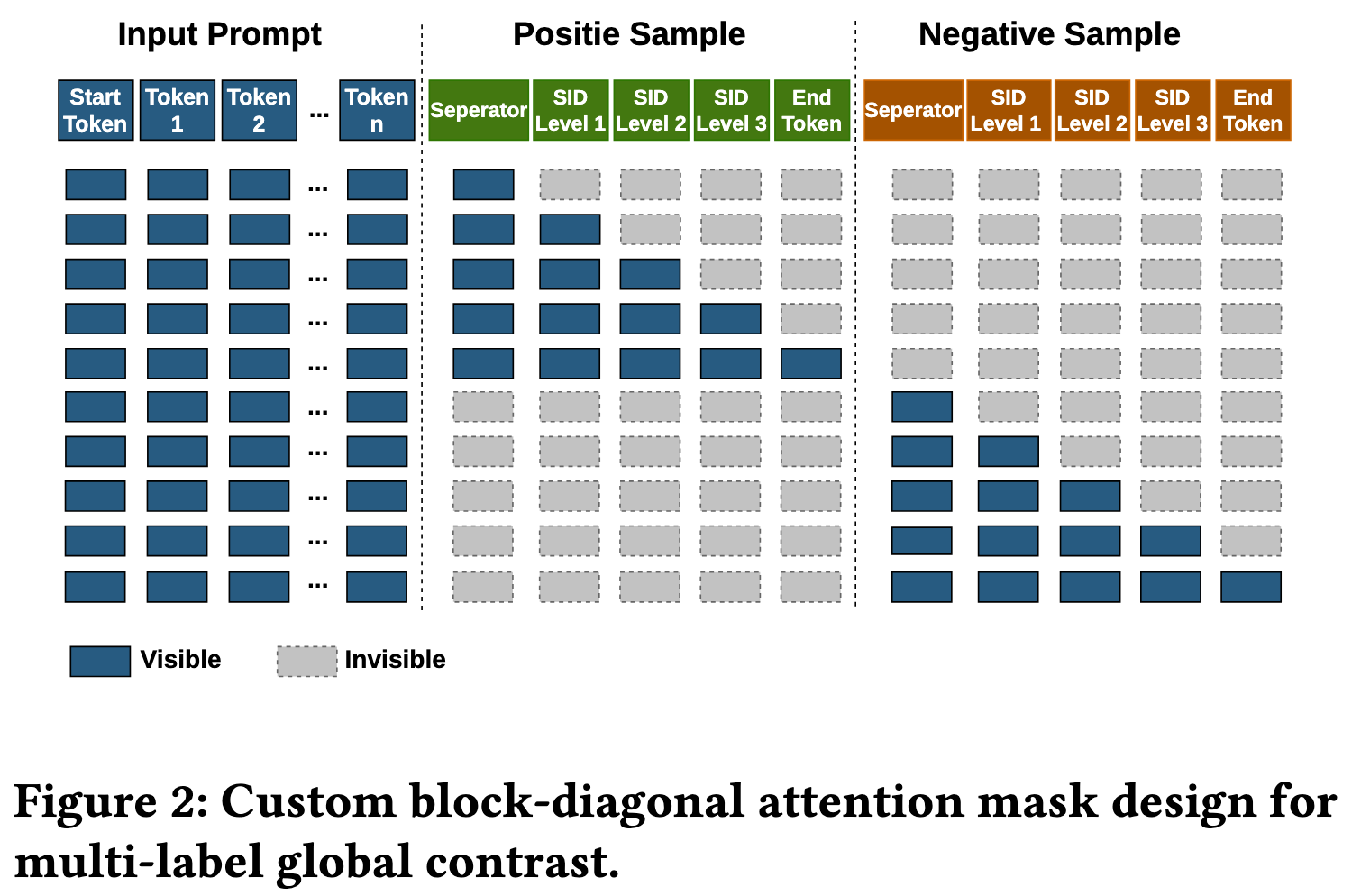
可以把 attention 可见性理解为:
| Token 区域 | 可见范围 |
|---|---|
| Prompt | 作为上下文,被所有 label 看到 |
| Positive Label | 只能看到 prompt 和自身历史 token |
| Negative Label | 只能看到 prompt 和自身历史 token |
| 不同 Label 之间 | 互不可见 |
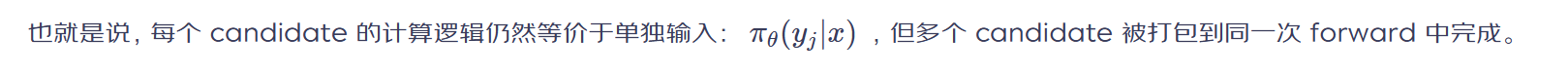
4.2 Attention Mask 与 Position ID 的两个关键细节

4.3 性能收益
从工程视角看,Label Packing 和 reference-free 设计保证了 RAD-DPO 可以在大规模搜索日志上高效训练,训练效率和SFT处于同一水平,远高于GRPO等强化学习算法。
显存:由于去掉了参考模型(SimPO 路线),显存消耗降低近50%。
吞吐:对比传统拼接方式,单次前向即可完成所有样本计算,训练吞吐提升了 300%。
5. 实验分析
为高效验证离线指标,我们在3千万小数据集上进行了对比实验,实际上线前的训练会放大到上亿量级的数据,经验证RAD-DPO训练后的指标提升会更明显 。
整体对比:
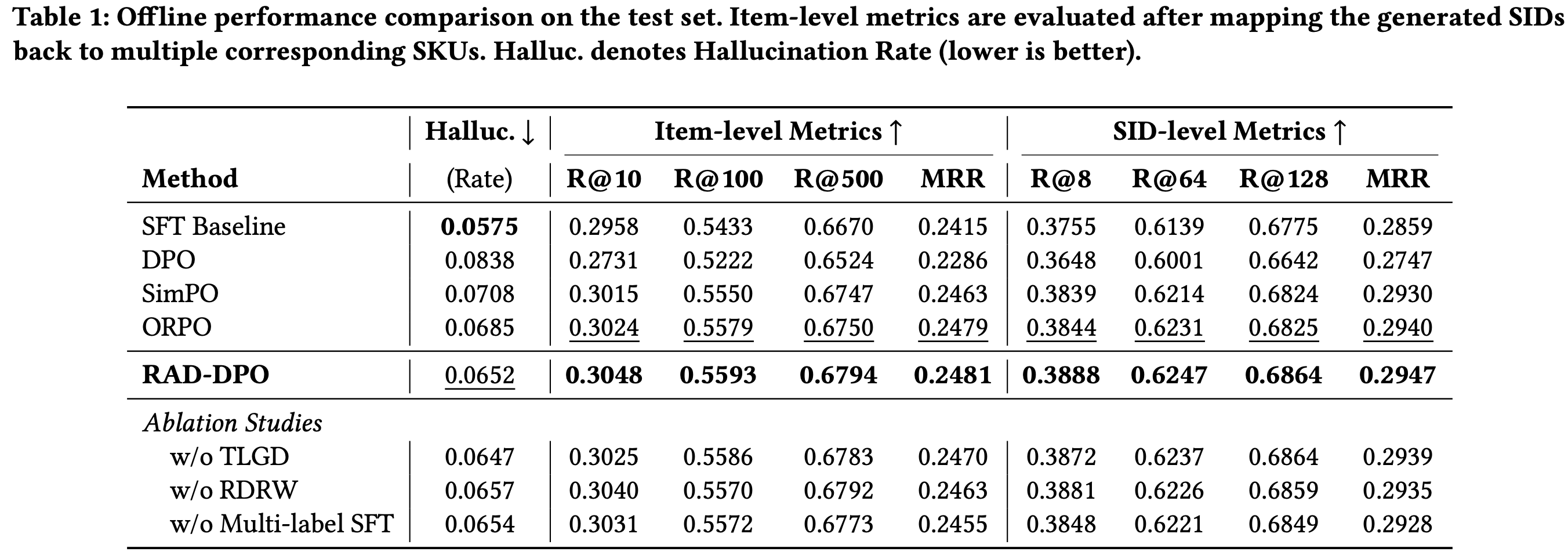
全方位领先:在所有召回(Recall)和 MRR 指标上,RAD-DPO 均优于 SFT 及其他 DPO 变体 。
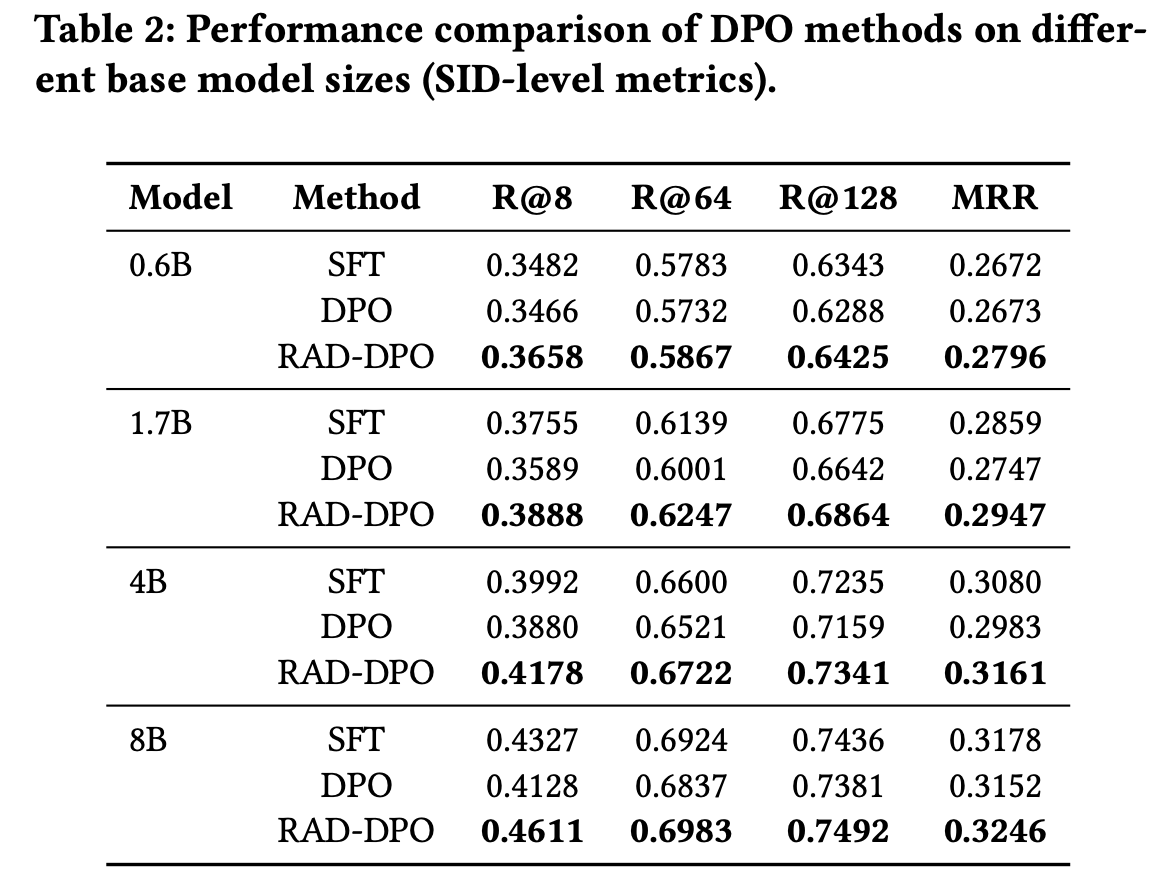
模型规模可扩展性:随着模型参数从 0.6B 扩展到 8B,RAD-DPO 的领先优势持续扩大(如 8B 模型下 SID-level MRR 提升至 0.3246) 。
数据效率: Figure 3 显示,即使在 10M 的训练数据下,RAD-DPO 依然能保持对 SFT 的显著相对提升 。
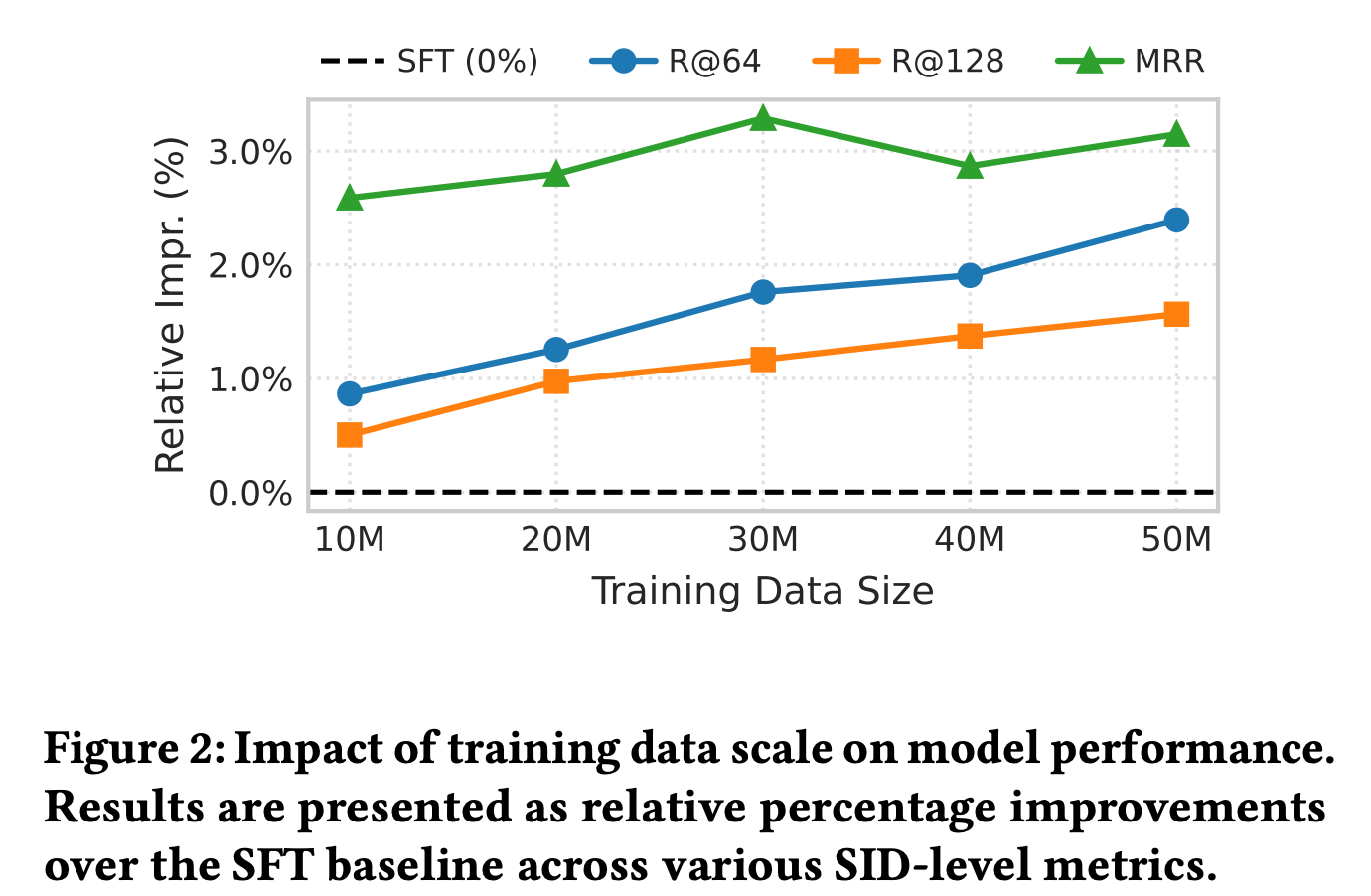
需要强调的是,论文中的结果为了对比公平,统一只使用了3000万条训练样本,实际上线时RAD-DPO可高效训练上亿数据,指标会有进一步提升。
6. 总结与展望
RAD-DPO 是生成式检索从理论走向大规模工业应用的关键方案 。它系统性地解决了结构化 SID 生成中的前缀冲突、隐式噪声以及多标签概率挤压问题 。通过 TLGD 梯度截断保护了层级结构的稳定性,通过 RDRW 实现了自适应降噪,并在工程上利用 Label Packing 实现了极高的训练吞吐 。
未来优化:
引入更丰富的样本类型:探索引入相关性样本,进一步提升检索结果的相关度(pgood) 。
训练阶段融合:探索 SFT 与 DPO 的单阶段联合训练,减少分阶段训练带来的分布偏移和成本增加。
精细化 Token 优化:针对不同位置的 Token设计差异化的损失权重,进一步挖掘生成式模型的建模能力 。
相关工作论文:
[1] DPO: Direct preference optimization: Your language model is secretly a reward model
[2] SimPO: Simple Preference Optimization with a Reference-Free Reward
[3] ORPO: Monolithic Preference Optimization without Reference Model
[4] Softmax-DPO: On Softmax Direct Preference Optimization for Recommendation
[5] IRPO: Implicit Policy Regularized Preference Optimization
[6] TDPO: Token-level Direct Preference Optimization
[7] AAO: Ambiguity Awareness Optimization: Towards Semantic Disambiguation for Direct Preference Optimization
[8] Omni-DPO: A Dual-Perspective Paradigm for Dynamic Preference Learning of LLMs
[9] Beta-DPO: β-DPO: Direct Preference Optimization with Dynamic
[10] APAO: Adaptive Prefix-Aware Optimization for Generative Recommendation
[11] RAD-DPO: RAD-DPO: Robust Adaptive Denoising Direct Preference Optimization for Generative Retrieval in E-commerce
[12] OneSearch-V2: OneSearch-V2: The Latent Reasoning Enhanced Self-distillation Generative Search Framework
[13] List-wise DPO: OneSug: The Unified End-to-End Generative Framework for E-commerce Query Suggestion





