



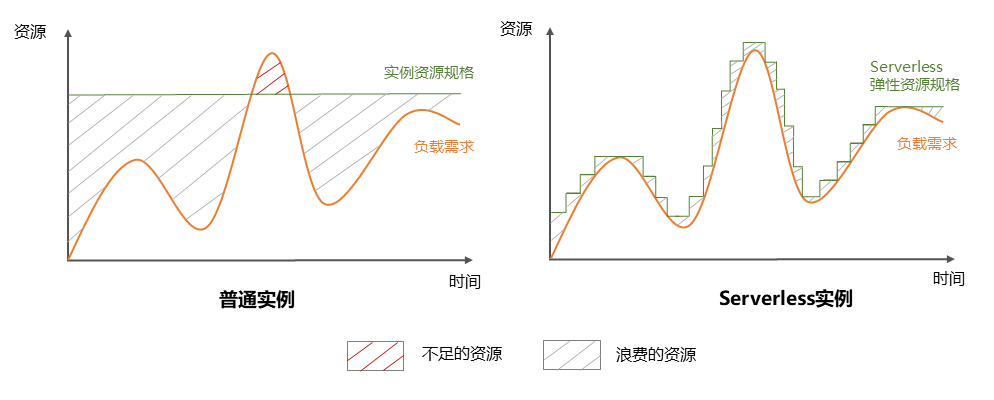
背景
在 AI 技术快速发展的当下,算力已成为各大厂商争相抢占的核心战场,随之而来的存储资源和服务器供应紧张问题也日益凸显。降本增效因此成为今年各大厂必须攻克的关键课题。DTS作为数据流转的核心枢纽,在单元化建设、AI基建、异构数据同步等场景中的应用广泛,资源消耗近年来也增长迅猛。如何在确保数据同步服务高可靠的同时,实现资源利用率的最大化,已成为DTS团队当下棘手的问题。
本文将深度拆解泰山DTS资源调度全链路优化实践,从指标体系重构、垂直扩缩容升级、资源池化协同到弹性调度, 完整呈现一套“监控-调度-优化-复盘”的闭环的解决方案,该方案最终实现CPU资源节流、CPU部署密度(同步管道/CPU核心)提升、 随业务流量动态调整资源的核心目标,为同类无状态的工具类基础设施优化提供可复用的解决方式与实践参考。
DTS介绍
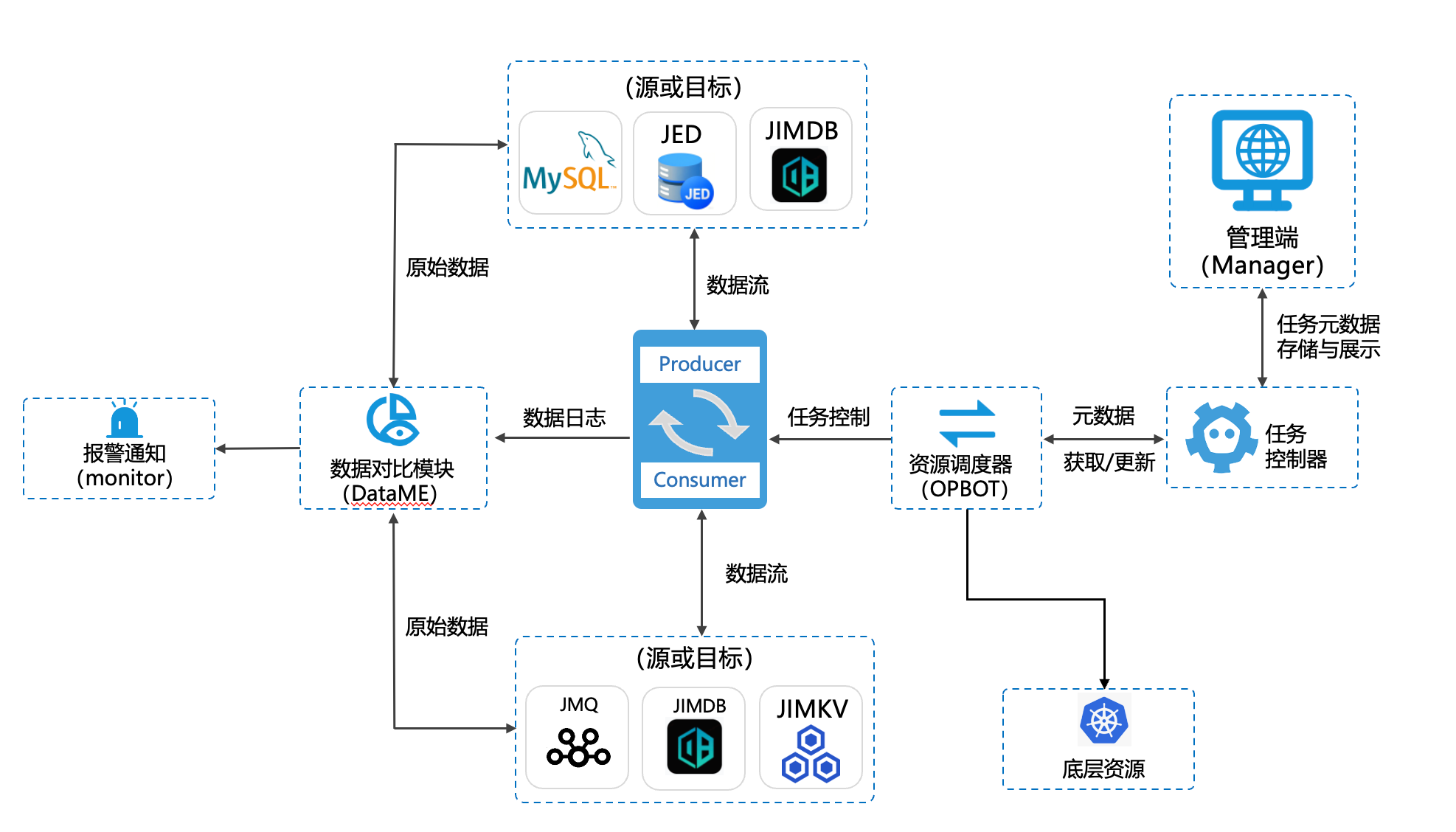
DTS是将各种中间件或数据库的数据从源端同步到目标端,整体的数量流可以参考以下的架构图:
资源分配的痛点
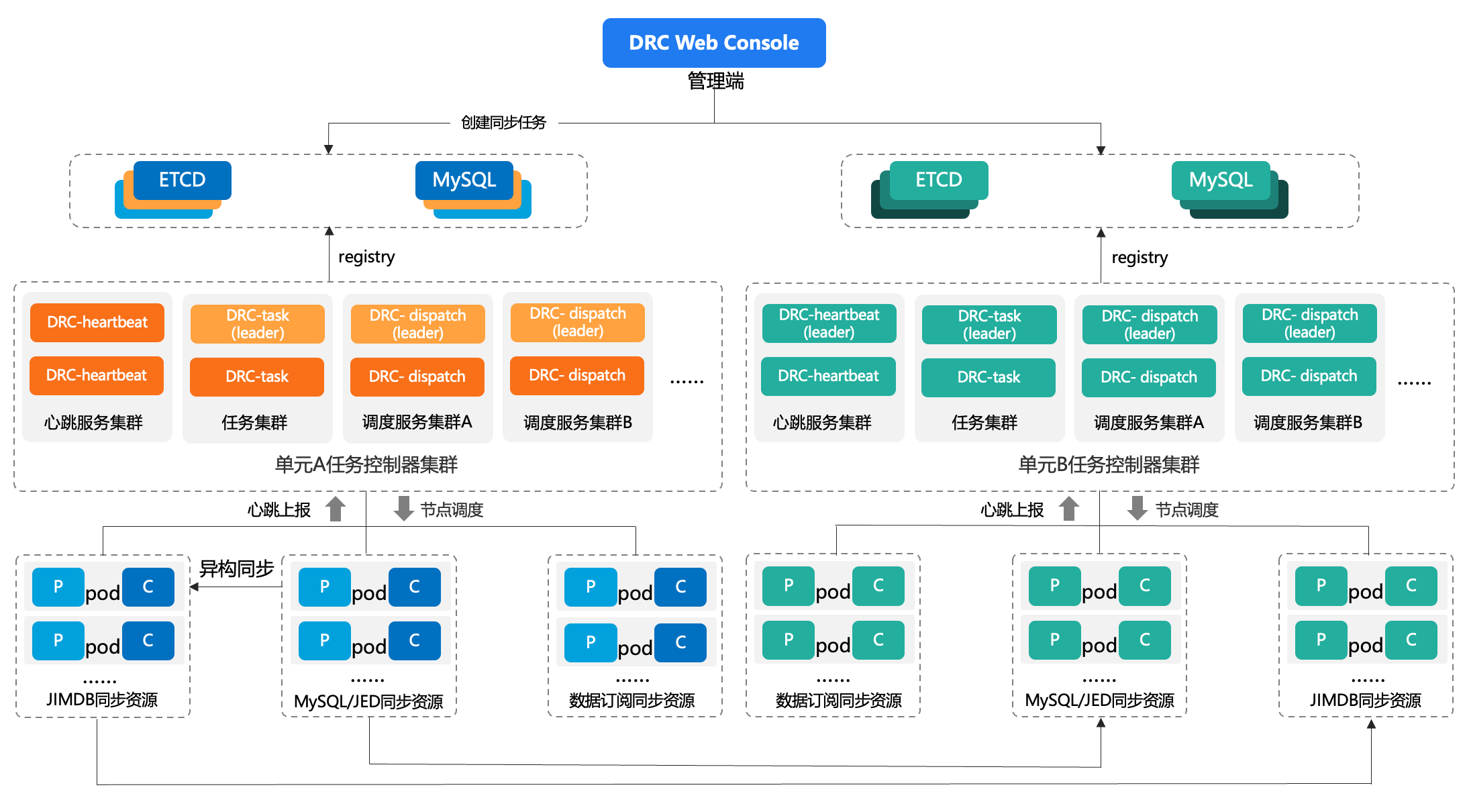
DTS的部署资源参考上图的JIMDB同步资源、MySQL同步资源,当前都是固定的容器规格。随着集团内大面积在推广老旧MySQL下线和单元化建设,DTS承载的任务量增长明显,传统固定分配的调度模式的弊端日益凸显,逐渐陷入快速扩张与降本提效的两难困境:
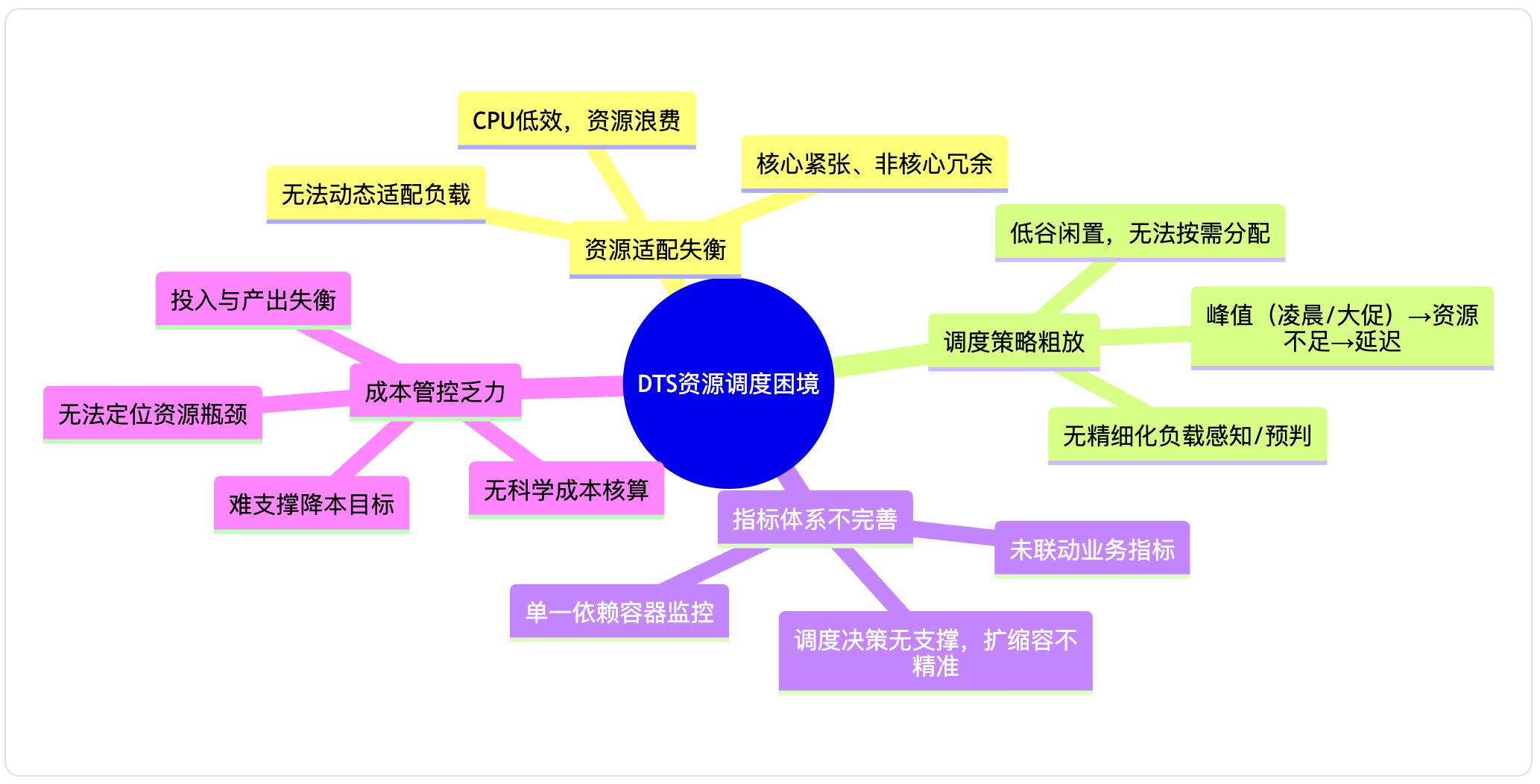
- 资源适配失衡:采用固定配额分配模式,无法根据任务负载动态调整资源,导致核心任务资源紧张、非核心任务资源冗余,CPU使用率长期处于低效区间,资源浪费严重;
- 调度策略粗放:缺乏精细化的负载感知与预判机制,面对业务峰值(如凌晨刷数、大促流量)易出现资源不足导致数据延迟,低谷期则造成资源闲置,无法实现“按需分配”;
- 指标体系不完善:单一依赖容器监控指标,未与业务指标深度联动,导致调度决策缺乏全面数据支撑,扩缩容触发不精准,甚至影响业务稳定性;
- 成本管控乏力:缺乏科学的资源成本核算体系,无法精准定位资源利用瓶颈,难以支撑整体降本目标的落地,资源投入与业务价值产出失衡。
调度重构
优化重构的前提的是“可度量、可量化、可观测”,本次实践首先重构了DTS资源调度的指标度量体系,建立“资源指标+业务指标”双维度监控体系,并重新设计了一套资源成本核算方法,为后续调度策略优化提供精准的数据支撑。
双维度监控体系
打破传统单一监控模式,覆盖所有同步容器与DTS任务,实现“技术指标监控+业务效果校验”的双向联动,确保调度决策既符合资源利用需求,又不影响业务正常运行。
| 指标类型 | 指标名称 | 采集频率 | 核心价值 |
| 资源指标 | CPU使用率(均值) | 1次/分钟 | 垂直扩缩容、Serverless调度触发的核心依据,直接反映资源利用状态 |
| 容器负载(均值) | 1次/分钟 | 辅助判断资源负载压力,避免单一CPU指标的局限性 | |
| 网络流入/流出速率(均值) | 1次/分钟 | 辅助评估网络瓶颈,为资源调整提供多维度参考 | |
| 业务指标 | 数据延迟(最大值) | 1次/分钟 | SLA保障核心指标,作为扩缩容触发的关键校验条件,确保业务不受影响 |
| 数据吞吐量(均值) | 1次/分钟 | 辅助评估容器负载合理性,优化资源分配精度 | |
| 业务定时的刷数任务 | 1次/天 | 在线业务和大数据的刷数,辅助周期性扩缩容 |
为确保监控数据的准确性与可用性,建立主动回调+按需拉取+定期复盘的数据采集与校准机制:
- 机器监控(主动回调):创建DTS资源时嵌入所需机器监控指标,配置JMQ指标消费,当指标达到阈值时实时回调DTS管控台,按任务维度记录数据,为资源调整与复盘提供依据;
- 任务监控(按需拉取):任务定期上报心跳(携带延迟数据)至Titan平台,当机器指标触发阈值回调后,管控台同步拉取延迟数据,双重校验是否需要调整资源,避免误调度;
- 复盘校准(定期优化):每周开展指标复盘,分析任务负载波动规律、扩缩容触发合理性、阈值适配性及资源利用瓶颈,为阈值校准与策略优化提供数据支撑,形成监控-复盘-优化的闭环。
成本核算
引入任务CPU部署密度”作为核心成本核算指标,构建可量化、可追溯的成本统计体系,实现资源成本的精细化管控与瓶颈定位。其核心计算公式如下:
公式说明:
| 符号 | 说明 | 取值 / 精度 |
| CPU使用密度,即该小时内同步管道 / 核数比的平均值 | 保留 2 位小数 | |
| 1 小时内的分钟采样点总数 | 固定为 60 | |
| 分钟采样点序号 | i=1,2,…,60 | |
| | 第i分钟运行中的 DTS 任务总数 | 保留整数 |
| 第i分钟所有运行任务的 CPU request 值总和(核数) | 保留整数 |
同时,按业务部门、任务类型两个维度,每小时统计“同步管道/核数”数据,精准定位不同业务场景、不同任务类型的资源利用瓶颈,为后续分层优化提供明确方向。
三阶优化策略
基于完善的指标体系与成本核算方法,本次实践采用“垂直扩缩容→资源池化→Serverless弹性调度”的三阶优化路径,层层递进、协同联动,逐步提升资源利用率,实现降本与稳效的双重目标。
一阶优化:垂直扩缩容
垂直扩缩容的核心目标是提升单任务资源适配度,打破固定配额模式,根据任务实时负载动态调整CPU核数,将整体CPU使用密度提升至0.7/C,为后续优化奠定基础。
本次实践突破传统“单一阈值触发”的局限,结合DTS任务特性,设计精细化的扩缩容规则与阈值体系,兼顾调度精准性与业务稳定性:
- 精细化阈值设定:采用“时间窗口+多指标联动”的触发机制,避免频繁扩缩容。扩容阈值以5分钟为时间窗口,当CPU使用率≥80%、容器负载≥5或网络流量达到对应核数上限,且数据延迟较上个窗口均值上涨超20%时触发;缩容阈值以10分钟为时间窗口,当CPU使用率≤30%、容器负载≤1.0,且数据延迟波动小于上个窗口均值20%时触发。
- 分级变更与间隔控制:设计1C、2C、4C、8C、12C、16C的核数分级体系,采用逐级升降级机制,每次仅调整一个等级(如2C→4C、16C→12C),避免跨等级变更导致的性能波动;同时设定5分钟的最小变更间隔,从扩缩容完成时间开始计时,规避短时间内负载波动引发的频繁调度。
- 阈值动态校准:每周结合上周负载数据,调整各任务类型的阈值参数,校准范围控制在±5%以内,适配大促、业务迭代等场景的负载波动,校准后的阈值同步更新至DongMonitor告警配置,确保阈值的适配性。
垂直扩缩容流程
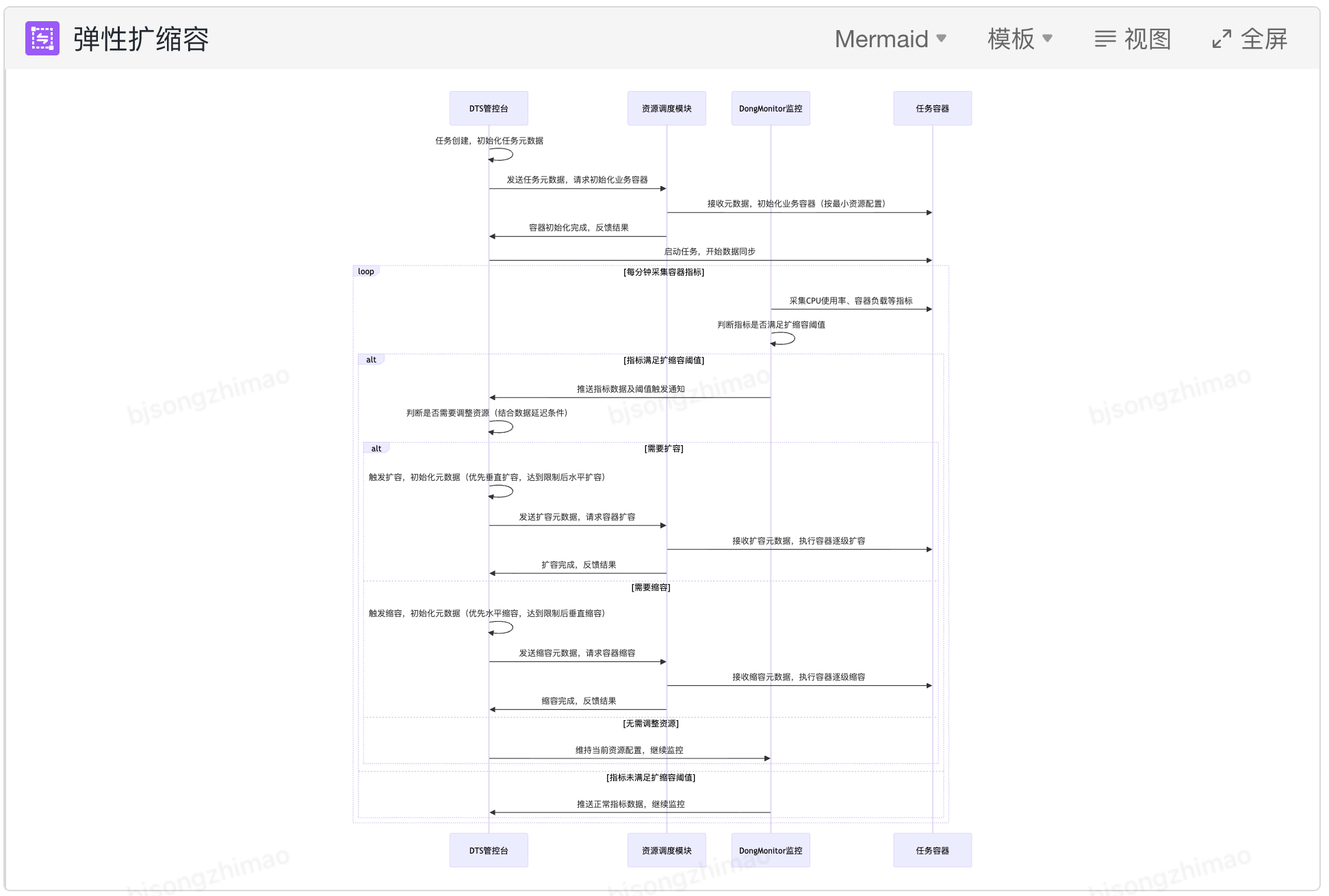
在 DTS 管控台侧实现垂直扩缩容回调接口,支持 DongMonitor 在触发阈值时的实时调用,需兼顾对任务状态、核数、变更间隔和任务延迟等多个扩缩容条件的判定。垂直扩缩容核心流程如下:
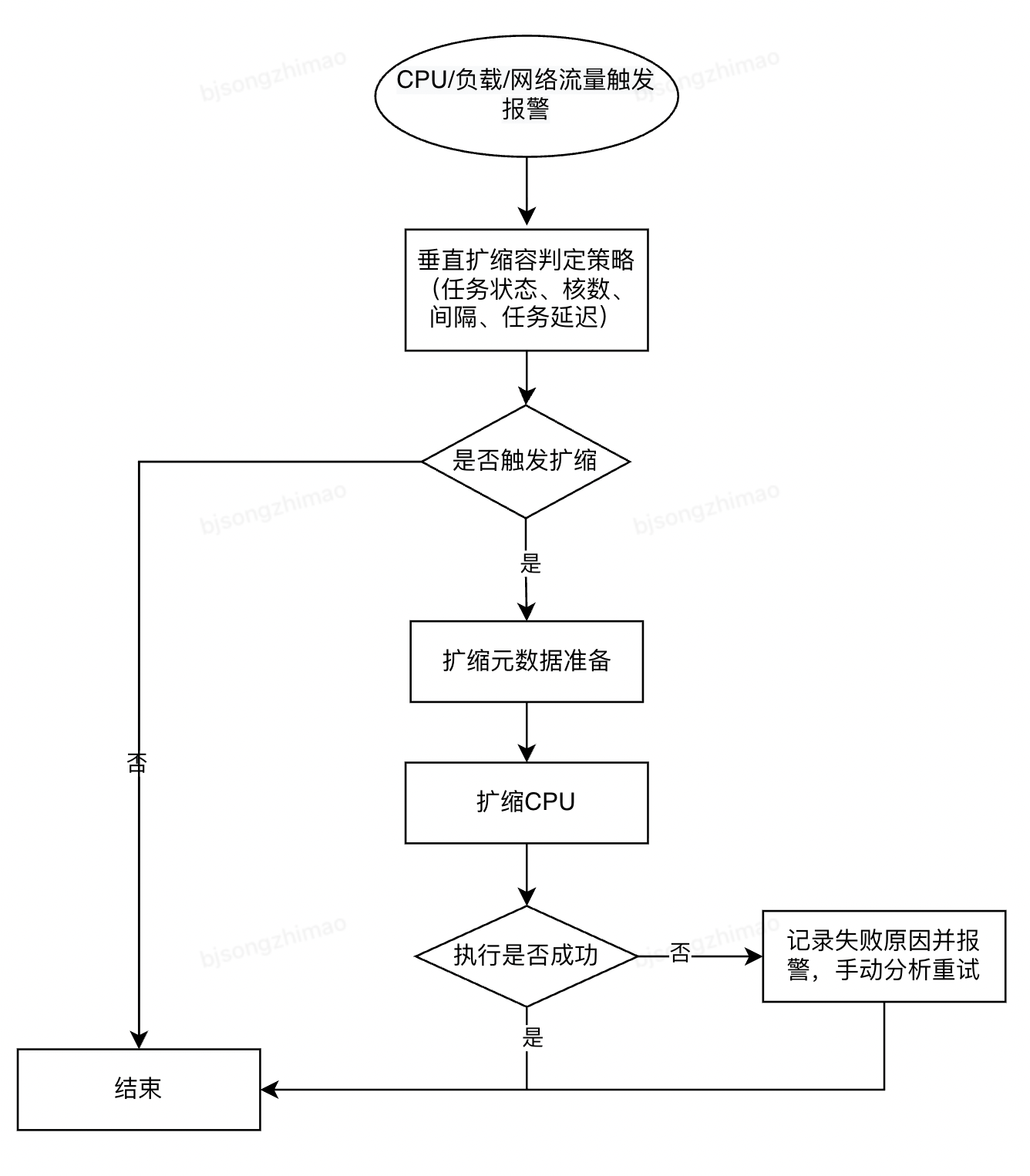
在流程层面,DTS管控台实现垂直扩缩容回调接口,支持DongMonitor在阈值触发时实时调用,同时兼顾任务状态、核数、变更间隔、任务延迟等多条件判定,形成“监控触发→回调请求→条件校验→扩缩容执行→结果复盘”的完整流程。
为保障优化落地的安全性,采用分层灰度推进策略,优先保障核心任务稳定性,灰度计划分四阶段推进,每阶段明确验证重点与验收标准,确保扩缩容成功率逐步提升,同时实现资源成本的阶段性降低。此外,建立完善的手动回退机制与固定配额任务管理体系,运维管理员可在发现负载异常、延迟升高等问题时,手动触发回退,将任务标记为固定配额,后续按月复盘优化后重新纳入自动扩缩容体系,最大限度降低优化风险。
二阶优化:任务共享资源池
在垂直扩缩容的基础上,引入任务共享资源池机制,实现非核心任务的资源集约化管理,与垂直扩缩容协同联动,进一步压缩资源冗余。
本次实践的核心思路是“分层隔离、动态适配”,基于任务等级、类型、所属业务域,构建差异化资源池,避免核心任务与非核心任务的资源竞争:
- 资源池分层划分:将P2、P3级非核心任务(含数据同步、增量数据订阅、数据迁移)纳入共享资源池,P0、P1级核心任务单独划分独立资源组,保障核心业务稳定性;共享资源池进一步分为P2资源池与P3资源池,P2资源池按交易、财经、本地生活等业务域划分,每个业务域共用一个资源池,初始配置为4C8G容器,资源冗余量控制在10%-15%;P3资源池采用集群共享模式,节点配置统一为4C8G,资源冗余量控制在5%-10%。
- 动态分配与回收:新任务创建时,管控台根据任务属性自动分配至对应资源池,分配前校验资源池容量,不足时自动触发水平扩容;任务暂停后自动释放资源,对于7天连续无流量任务发送邮件确认,超过1个月无增量流量则通知用户并暂停同步,实现资源的高效回收;当任务等级发生变化时,自动迁移至对应资源组(低等级转高等级迁移至独立资源组,高等级转低等级迁移至共享资源池)。
- 资源协同与异常隔离:共享资源池内所有任务纳入垂直扩缩容体系,根据实际负载动态调整CPU核数,实现池化管理+精准适配的双重目标;同时重点关注大key、频繁刷数、大事务等异常任务,为其添加标签,对频繁触发扩缩容的容器进行原因定位并迁移至独立资源组,避免影响池内其他任务。
此外,建立资源池动态调整机制,以天为单位巡检资源池冗余量,不足时触发水平扩容(补充至冗余10%),冗余量超5%时触发水平缩容;同时实现故障节点每分钟一轮的自动巡检与替换,确保资源池容量稳定,保障任务运行连续性。

三阶优化:弹性调度
作为优化体系的核心升级环节,Serverless弹性调度打破传统“被动响应”的调度模式,引入负载预判机制,与垂直扩缩容、资源池化深度协同,实现“负载预判-资源分配-负载上升-负载恢复-资源释放”的全流程自动化,最终将整体CPU使用密度提升至0.85/C,达成核心优化目标。
按需分配与动态适配
任务创建时,DTS管控台根据任务类型、等级,为其分配最小资源核数(默认1C),初始化容器并启动任务;任务运行期间,DongMonitor每分钟采集CPU使用率、容器负载、网络流量等指标,达到扩缩容阈值时,回调DTS控制台,触发动态调整资源核数:
- 扩容逻辑:连续5分钟满足CPU使用率≥80%、容器负载≥5或网络流量达到对应核数上限,且数据延迟较上个窗口均值上涨超 20%,触发垂直扩容,按逐级升级机制提升资源核数,最大不超过16C。
- 缩容逻辑:连续5分钟满足CPU使用率≤30%、容器负载≤1.0,且数据延迟小于上个窗口均值波动小于20%,触发垂直缩容,按逐级降级机制降低资源核数,直至恢复最小1C配额。
负载预判模型
针对数据同步峰值场景(如凌晨刷数、业务突发增量、节假日波动),基于前一周历史负载数据(CPU使用率、数据流量、延迟数据),构建“同期加权滑动平均法+分时段精细化预判法”的负载预判模型,实现“提前调度、主动适配”,彻底解决峰值资源不足、低谷资源闲置的问题。
同期加权滑动平均法在传统7天同期均值基础上优化,通过异常值清洗与时间衰减权重提升预判准确性:首先剔除大促、故障、任务中断等场景的异常数据,避免拉偏预判结果,异常值判定标准为
,其中为t时刻7天历史数据均值,为对应标准差);随后按“越近日期权重越高”的原则,采用权重分配(从最近1天到最远7天),计算单采样点预判值,贴合最新业务趋势。
分时段精细化预判法则基于单采样点预判结果,进行30分钟窗口化聚合计算(其中M=30为窗口内分钟采样点数),替代单日单峰值的粗放预判,精准识别日内多段高峰与低谷,匹配对应资源规格,减少无效资源占用。
在调度执行层面,每日23:00执行预判模型计算,输出次日峰值起止时间与负载强度,生成定时调度任务;峰值时段前30分钟,提前触发资源扩容(优先垂直扩缩容,超单实例承载能力则新增实例);峰值过后30分钟,销毁闲置容器并执行垂直缩容,恢复最小资源配额,实现资源的全生命周期高效利用。
针对数据同步峰值场景(如每日凌晨刷数、业务突发增量流量、节假日流量波动),基于前一周的历史负载数据(CPU使用率、数据流量、延迟数据),采用"同期加权滑动平均法+分时段精细化预判法"构建负载预判模型,实现“提前调度、主动适配”。
同期加权滑动平均法
在原有 7 天同期均值逻辑基础上优化,通过异常值剔除消除无效数据干扰,通过时间衰减权重强化近期业务趋势,核心计算分为两步
1. 异常值清洗:
剔除大促、故障、任务中断等场景的异常历史数据,避免拉偏预判结果,公式如下:
其中为时刻 7 天历史数据的均值,为对应标准差;剔除满足的异常样本,保留清洗后的有效数据。
2.时间衰减加权预判计算:
对清洗后的有效数据,按 “越近的日期权重越高” 的原则计算单采样点预判值,贴合最新变化趋势,公式:
其中默认权重分配(从最近 1 天到最远 7 天)取值为。
3.分时段精细化预判法
基于同期加权滑动平均的单采样点预判结果,做窗口化聚合计算,替代单日单峰值的粗放预判,精准匹配日内多段高峰、低谷的负载特征,减少无效资源占用,核心公式如下:
其中为单个窗口内的分钟采样点数,为第个 30 分钟窗口的平均负载预判值;基于窗口预判值,可精准识别日内连续高峰 / 低谷时段,匹配对应资源规格。
4.调度适配执行规则
- 峰值预判:每日 23:00 执行上述预判模型计算,基于窗口平均负载预判值识别连续峰值时段,输出次日峰值起止时间、峰值负载强度,生成定时调度任务
- 峰值适配:峰值时段前30分钟,提前触发资源扩容,先通过垂直扩缩容提升当前实例CPU核数至预设峰值配额;若预判负载超过单实例最大承载能力(16C),则自动新增实例,分担任务负载,避免延迟升高。
- 低谷适配:峰值过后30分钟,触发销毁闲置容器实例,再对留存实例执行垂直缩容,逐步恢复最小资源配额,释放冗余资源。
性能验证与灰度落地
以JIMDB同步任务为例,Serverless任务的吞吐与核数的参考关系如下表所示,实际性能可能因网络环境、源实例和目标实例类型和性能、延迟等因素的影响而有所差异
| 容器规格 | CPU使用率 | 吞吐上限参考值(MB/s) | RPS上限参考值 |
| 2C8G | 80% | 50 | 13w |
| 4C8G | 80% | 130 | 26w |
| 8C8G | 80% | 270 | 51w |
| 12C8G | 80% | 370 | 74w |
| 16C8G | 80% | 500 | 100w |
以JIMDB同步任务为样本,Serverless任务的性能表现与资源规格呈现明确的正相关关系,16C8G容器在CPU满负荷运行时,吞吐上限可达500MB/s,OPS上限达100w,完全满足各类DTS任务的性能需求。
落地成效
26年Q1期间CPU 资源节约5.3W核,整体缩容了近20%,核心 DTS 任务峰值延迟控制在 200ms 以内,完全满足 SLA 要求;部分刷数的场景已实现业务高峰提前 30 分钟预扩容、低峰自动缩容的弹性能力,为后续精细化账单管理打下坚实基础。
结束
通过近期 DTS 资源调度的一系列优化实践,我和团队的伙伴们,真切地感受到了资源效率持续提升带来的喜悦,也深刻印证了一个规律:单纯优化单节点性能,往往难以拿到全局最优的结果。只有性能优化与全局调度体系升级双向结合,才能真正实现长效降本,为用户带来实打实的成本节省。
未来,调度优化、精细化管控将成为数据同步服务的核心发展方向。希望本次实践能够为同类产品提供借鉴,推动数据基础设施从可用向高效、智能、低成本的全面升级。





