



GROLE: Instance-Level Group Relative Optimization for LoRA Experts in Incremental Learning
摘要
大型语言模型(LLMs)在零样本泛化方面表现出色,但将其应用于下游任务或改变数据分布通常需要持续的微调,这一过程容易出现灾难性遗忘现象,并且新旧知识迁移有限。这种挑战在任务边界模糊且数据以非平稳的流形式不断到来在线增量学习环境中尤为明显。为了解决这些问题,我们提出了 GROLE(基于专家的组相对优化)方法,它逐步构建一个由冻结的、任务特定的LoRA专家组成的池,并使用一种轻量级的、实例级别的专家选择器,通过组相对强化学习目标进行优化。该实例级选择器通过动态地合并相关的专家以最大限度地提高模型的适应性与稳定性。在各种增量学习基准上的实验表明,GROLE 优于现有最优方法,特别是在无任务和模糊边界的情况下,实验结果验证了方法在可塑性和鲁棒性的有效平衡。
引言
大语言模型(LLM)展现出强大的零样本泛化能力,但在下游任务上要达到最佳表现,仍需任务特定的微调。这种对齐过程将领域知识注入模型,但也带来了成本瓶颈:每新增一个任务都需要重新训练全量数据,存储和训练开销成倍增长,难以实现模型的高效迭代。
增量学习(Incremental Learning, IL)为此提供了一种可行的解决方案。有效的增量学习系方法需要兼顾两个目标:
- 克服灾难性遗忘(Catastrophic Forgetting, CF):模型在新任务上更新参数时,不能导致旧任务性能退化;
- 促进知识迁移(Knowledge Transfer, KT):系统应能复用共享结构加速未来学习,甚至通过逆向迁移优化早期任务。
LoRA 等参数高效技术通过低秩矩阵表示任务特定更新,大幅减少了存储开销,因而特别适用于增量学习场景下新任务持续到达所需的快速迭代与低开销存储。然而,大多数基于 LoRA 的 IL 方法存在以下不足:
- 单一 LoRA + 正则化:维护单一 LoRA 并约束其参数漂移(如 O-LoRA),在模糊边界下遭受严重遗忘;
- 独立 LoRA + 任务 ID:为各任务部署独立专家,但推理时需要显式任务 ID,在真实无任务场景中不可行。
本文首次建立实例级权重优化与 LoRA 增量学习之间的联系,提出 GROLE 框架,包含以下创新点:
- 实例级专家选择:在自适应选择器训练过程中,为每个输入样本动态预测最优的 LoRA 专家合并权重,提高模型对不同任务的泛化能力;
- 基于 GRPO 的梯度无关优化:通过强化学习规避合并权重在 LLM 梯度回传时的不稳定性,并利用模型自身的交叉熵损失作为奖励信号,提高选择器网络训练稳定性;
- Dirichlet 采样探索策略:利用 Dirichlet 分布在概率单纯形上的天然支持,实现合并权重在训练时 exploration 和 exploitation 的自动平衡。
GROLE 将实例级自适应路由机制引入 LoRA 增量学习框架,通过轻量化LoRA选择器在严格参数隔离和动态知识迁移之间建立了联系。大量实验表明,在不同数据划分策略和benchmark上,GROLE 优于现有最优方法,验证了方法的有效性。
方法
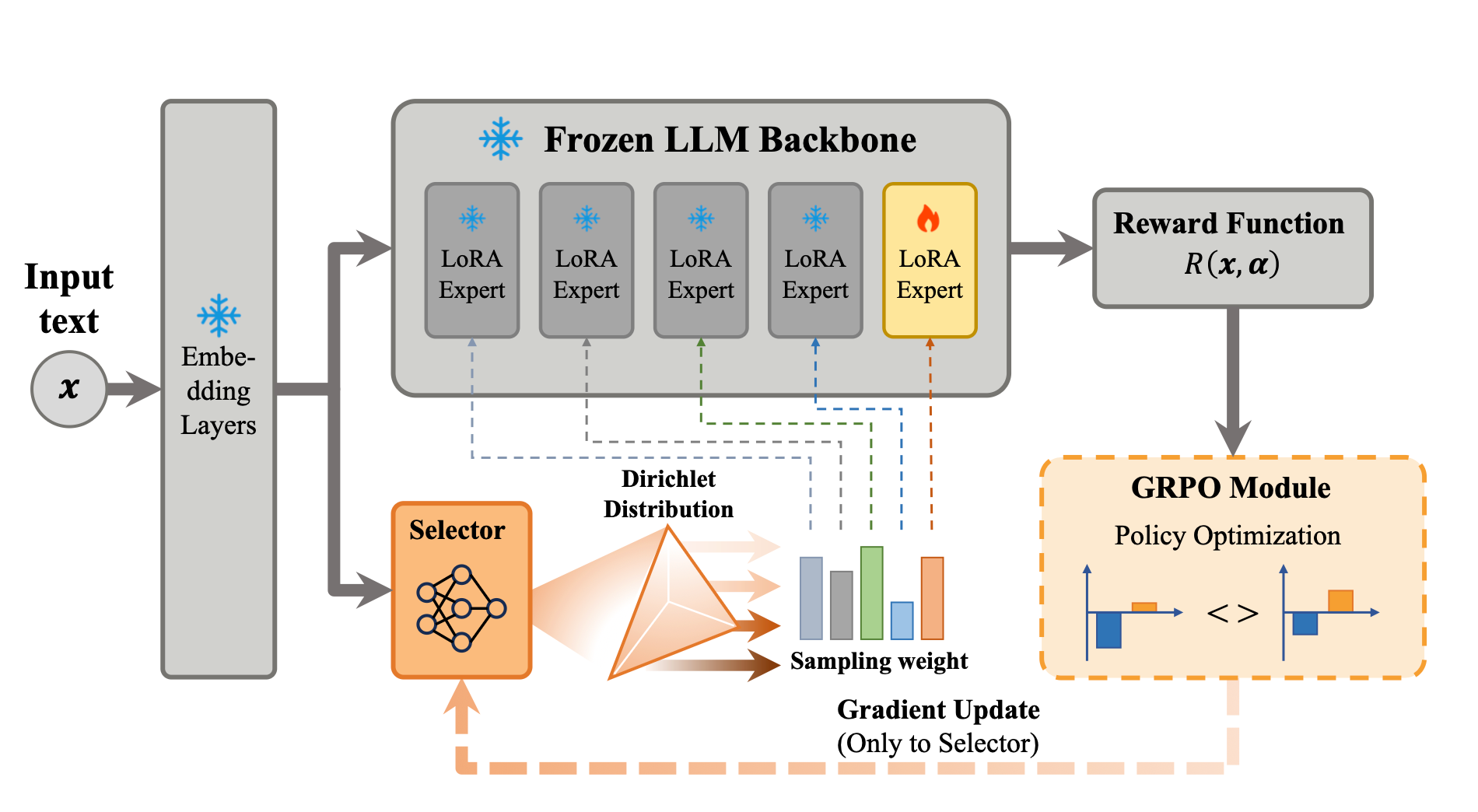
GROLE 的核心思想是两阶段训练范式。第一阶段增量式学习任务专属 LoRA 专家,第二阶段冻结所有LoRA参数,通过强化学习训练实例级轻量化选择器动态合并专家。
1. 问题形式化:实例级增量学习
在真实场景中,任务边界往往是模糊的,数据分布随时间持续演化。我们将实例级增量学习形式化为一个通用框架:
考虑一个顺序数据流 ,其中 代表第 个任务的数据。值得注意的是,我们采用广义的任务定义:一个任务甚至可以定义为单个时间窗口内的数据,无需预定义的语义边界。
同时,设预训练主干为 ,专家参数池为 ,权重空间 。对于流数据 中的输入 和标签 ,实例级 IL 的目标可写为:
其中 表示交叉熵损失函数。对于给定适配器层,输出 为:
现有方法遵循两种主导范式:正则化方法优化共享专家或专家池,通过惩罚参数偏差来缓解遗忘;或者为不同任务独立训练个性化专家,通常在推理时需要显式任务 ID。这些方法均依赖静态权重分配,无法适应数据分布的实例级变化。相比之下,我们提出了动态权重优化的视角,与其将专家合并视为预定的或任务级策略,不如为每个样本学习最优合并权重。
动态权重优化的挑战:最直接的思路是在 SFT 阶段联合优化 和基础模型,或通过轻量网络生成它们。但这种策略因漫长的反向传播路径而遭受优化不稳定性,即 的梯度必须穿越 LLM 的所有层,常常导致梯度消失或不稳定信号。
2. 面向 LoRA 专家的分组相对优化(GROLE)
为规避这一问题,我们提出基于 RL 的梯度无关替代方案,利用模型最终输出导出的标量奖励来指导 的优化,从而完全避免通过 LLM 进行误差反向传播,提高训练稳定性。
阶段一:基于 SFT 的任务专属 LoRA 专家
在第一阶段,我们增量式构建一组 LoRA 专家来捕获任务特定知识。具体而言,在每个时间步 ,为当前任务 实例化一个新专家并添加到已有专家集合中。
给定冻结参数的预训练主干模型 ,每个 LoRA 专家 由两个低秩矩阵 参数化,且 。为简洁起见,设 ,即为每个任务分配专属 LoRA 专家。对于每个任务 ,相应的专家 在 上通过 SFT 优化,同时保持 和所有先前专家 冻结。完成增量训练后,完整参数集 被冻结,作为下一阶段实例级合并的基础。
阶段二:基于 RL 的自适应合并权重选择
在第二阶段,我们采用强化学习训练轻量级选择器 ,为每个样本预测实例级合并权重
采样策略:为使选择器学习到有效的合并权重,我们首先将权重空间定义为概率单纯形 ,将选择器输出 视为浓度参数 ,采用 Dirichlet 分布 进行采样。Dirichlet 分布具有两个理想性质:一是采样权重 天然满足概率单纯形约束;二是 由浓度 控制,从而低浓度产出更分散的样本(促进探索),高浓度则产出集中在均值附近的样本(利于利用)。训练过程中,选择器的输出浓度天然会先小后大,实现探索和利用的自动平衡。
奖励函数:我们采用阶段一的 SFT 模型直接作为奖励模型。这确保了奖励信号与下游目标完全对齐。具体而言,给定状态 、行动 的奖励定义为:
其中 表示交叉熵损失。使用奖励裁剪 来约束奖励信号的数值范围,因为不同样本的原始损失值可能波动数个数量级,导致梯度不稳定。同时,裁剪机制使模型能够绕过简单样本( )或困难样本( ),有效稳定优化过程。
优化目标:选择器的优化目标遵循 GRPO 框架,通过消除价值函数来简化训练。对于每个样本 ,选择器采样 组权重 ,计算各自的奖励 。行动 的优势通过组内比较计算:
完整优化目标为:
其中 是重要性采样比率, 是裁剪阈值。由于选择器是随机初始化的,相比于标准 GRPO 优化目标我们省略了 KL 正则项。
训练结束后,选择器直接输出确定性权重 用于推理。
实验结果
数据集与基准
我们在两大广泛使用的文本分类基准上评估:
- Standard CL Benchmark:AG News、Amazon、Yelp、DBpedia、Yahoo Answers 中选取 4 个任务;
- Large Number of Tasks:扩展至 12 个任务,涵盖标准 CL、GLUE(MNLI、QQP、RTE、SST-2)与 SuperGLUE(WiC、CB、COPA、MultiRC、BoolQ)以及 IMDB。
为模拟真实在线环境中任务边界模糊、数据流式混杂的场景,我们采用三种划分策略:
- Srd-1:标准顺序训练,任务间无重叠;
- Srd-4:将每个任务切分为 4 个碎片并随机重排,提高任务数据的重叠程度;
- Dir-0.3:从 Dirichlet(0.3) 分布采样分配样本,形成任务边界高度模糊的连续数据流。
评价指标
采用平均准确率(Average Accuracy, AA):评估模型在所有个任务上的平均表现,其中表示模型训练了第个任务后在第个任务上的测试准确率。该指标同时捕捉:
- 时的后向迁移(是否遗忘);
- 时的前向迁移(能否零样本泛化到未来任务)。
基线方法
涵盖非增量上界(PerTaskLoRA、MTL)与增量基线(Replay、SeqLoRA、IncLoRA、O-LoRA、MultiLoRA、MoELoRA、MTL-LoRA)。
主要实验结果
| 方法 | Standard CL (Srd-1) | Standard CL (Srd-4) | Standard CL (Dir-0.3) | Large Tasks (Srd-1) | Large Tasks (Srd-4) | Large Tasks (Dir-0.3) |
| Replay | 72.70 | 72.32 | 72.78 | 62.44 | 76.54 | 77.08 |
| SeqLoRA | 69.25 | 73.78 | 72.92 | 71.92 | 73.23 | 75.10 |
| IncLoRA | 73.08 | 55.70 | 49.55 | 65.60 | 41.15 | 33.40 |
| O-LoRA | 73.65 | 73.45 | 68.15 | 72.69 | 57.77 | 44.50 |
| MultiLoRA | 66.90 | 70.10 | 69.60 | 74.08 | 70.98 | 70.21 |
| MoELoRA | 70.13 | 75.30 | 66.63 | 76.35 | 58.00 | 67.52 |
| MTL-LoRA | 74.78 | 76.60 | 70.68 | 72.23 | 73.13 | 64.98 |
| GROLE | 78.10 | 78.83 | 78.08 | 82.79 | 82.63 | 83.25 |
| PerTaskLoRA | 77.60 | 77.60 | 77.10 | 85.17 | 82.73 | 82.44 |
| MTL | 77.75 | 77.75 | 77.75 | 83.90 | 83.90 | 83.90 |
如表所示,GROLE 在 Standard CL 基准上较最优基线提升 4.32%,在 Large Number of Tasks 上提升高达 9.47%。更重要的是,在标准 CL 基准上 GROLE 甚至超越了 PerTaskLoRA 和 MTL 这两个非增量上界,证明实例级动态路由能够释放出超越静态多任务训练。
负迁移分析
在模糊边界场景(Srd-4、Dir-0.3)中,O-LoRA 等基于正交约束的方法出现显著性能衰减。严格正交虽能隔离参数干扰,却将共享特征强行约束到不相交子空间,阻碍了跨任务协同,导致负迁移。MultiLoRA 则因模块间隐式竞争和顶部奇异向量主导问题而训练不稳定。相比之下,GROLE 通过实例级路由持续实现正向迁移,在任务重叠度越高时优势越明显。
OOD 泛化能力
我们将 AG News 作为分布外(OOD)任务,仅在最终测试时评估。GROLE 在 OOD 任务上较最优基线提升 3.60%,且在不同划分策略下表现稳定。这表明 GROLE 能充分释放专家池的泛化潜力,对未见过的任务类型展现出较好的自适应能力。
其他对比实验
- 组大小(Group Size):从 的不同取值,性能波动仅约 0.6%,对超参不敏感;
- Top-k 专家激活:仅激活 Top-1 专家时性能已接近全激活,验证了选择器的正确选择。且随着激活专家数增加,性能稳步提升,验证多专家融合的必要性;
- 采样策略:Dirichlet 采样较 Gaussian 采样平均提升 0.81%(标准 CL)和 1.85%(多任务),单纯形约束带来的稀疏可解释权重优于无约束高斯噪声;
- 训练效率:选择器训练(Stage 2)在标准 CL 上耗时不足 LoRA 专家训练(Stage 1)的一半,且支持批量化实例级推理,兼顾了精度与效率。
小结
本文提出了 一种面向无任务边界与模糊任务边界的增量学习框架GROLE,它维护了一个不断增长的、由冻结的 LoRA 专家组成的专家库,并引入了一个基于组相对优势优化的轻量级选择器。该两阶段范式通过严格的参数隔离彻底消除了灾难性遗忘,并借助实例级的专家自适应融合实现了任务间的强知识迁移。模块化设计支持专家库的系统性扩展,选择器则保证了系统在动态场景下的灵活响应。实验表明,GROLE 在现有基准上实现了稳定性与可塑性的良好平衡,适用于复杂开放环境下的增量学习。





