



一、Agent Skill 自进化的通用思路
1.1 核心机制:目标 + 靶子 + 测试 + 主控评判 + 自动迭代
关键点:主控agent同时开启多个子agent并行执行任务,接受和测试子agent的结果,测试不通过反馈错误原因,子agent失败重试,自动迭代,直到主控agent找到符合要求的结果。
| 要素 | 说明 |
| 目标 | 明确任务要达成的状态,防止流程中途停止 |
| 靶子 | 已被验证的好答案,作为“接近标准” |
| 批量测试 | 多 Agent 并行尝试不同路径,同一轮探索多条路 |
| 主控评判 | 判断是否接近靶子,并指出差距所在 |
| 自动迭代 | 子agent结果不符合预期,根据主控要求,自动迭代,根据错误原因重新生成skill,循环往复 |
架构图:
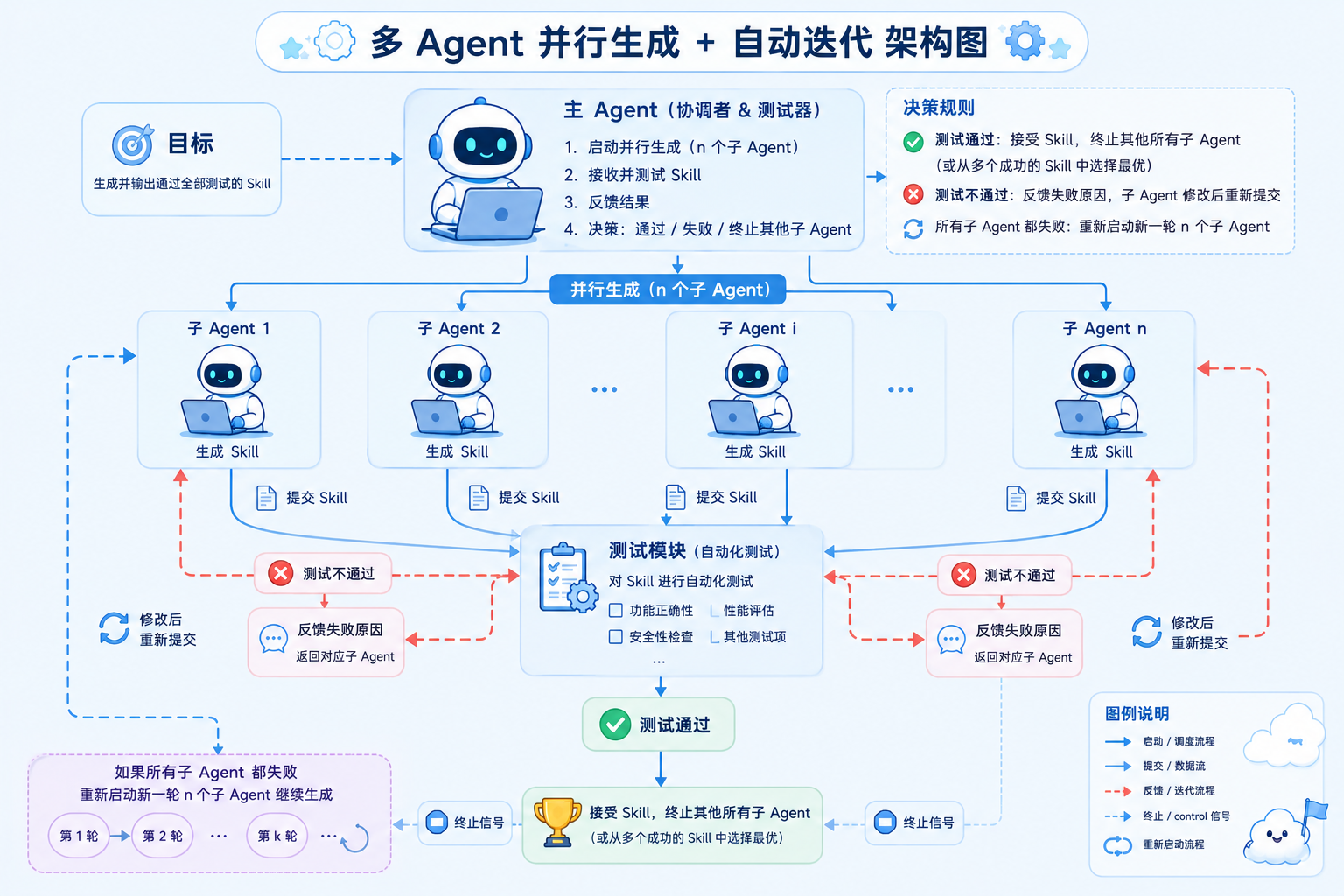
1.2 核心转变:从“调 Skill”到“训 Skill”
传统方式,人是操作者;自进化方式,人是目标设定者,Agent 是自主迭代者。减少了人机一轮一轮调试的人力成本和时间成本。
| 对比维度 | 传统方式:调 Skill | 自进化方式:训 Skill |
| 运作模式 | 人给素材 → Agent 跑结果 → 人不满意再补一句 → Agent 再跑一版 | 人给定目标 + 标准答案(靶子)→ Agent 围绕目标自主迭代 |
| 路径探索 | 单线执行,一轮只试一条路径 | 多线并行,一轮探索多条路径 |
| 停止机制 | 容易停止:结果不对就等人工接手 | 没接近目标就继续跑,不跑一版就停下来等人 |
| 本质特征 | 人机反复交互,结果驱动 | 自主训练迭代,目标驱动 |
| 最终产出 | 靠人逐步“调”出来的答案 | 一轮一轮尝试、逼近,答案自然浮现 |
1.3适用条件
该方法适用于具备“靶子”的任务,即满足以下条件:
- 能够对照结果进行判断(像不像、准不准、能不能继续改)
- 存在明确的质量或匹配标准
如果任务本身没有“好答案”的衡量标准,则难以进行有效训练。
二、为什么选择 CLI?——多 Agent 并行的关键能力
2.1 核心问题:为什么是 CLI 而不是 Web 端?
- Web 端:一次只能运行一个 Agent
- CLI 端:可以同时启动多个 Agent 并行执行,成倍提升全流程效率
2.2 单 Agent vs 多 Agent 的质变维度
| 维度 | Web 端(单 Agent) | CLI(多 Agent 并行) |
| 执行方式 | 一次一个方案,跑完再想下一个 | 同时启动 5–10 个子 Agent,各自独立实现 |
| 试错效率 | 一轮一条路,受限于串行 | 一轮多条路,批量探索不同解法 |
| 方案多样性 | 依赖人反复调整提示词 | 主 Agent 生成多条“训练线索”,子 Agent 分头尝试 |
| 收敛速度 | 慢,需多轮人机交互 | 快,一轮即可对比多个方案的优劣 |
| 自动化程度 | 需要人持续介入决策 | 主 Agent 自动评判、自动重试、自动收敛 |
三、三层协作模式
┌─────────────────────────────────────────────────────────┐
│ 第1层:我(用户) │
│ 角色:需求方 + 审核者 │
│ 动作:描述目标和靶子,不写代码,不设计细节 │
│ 最后审核哪些方法值得写回、哪些规则该删 │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 第2层:AI助手(如Claude Web/App端) │
│ 角色:提示词工程师 / 训练规则设计师 │
│ 动作:把我的模糊需求,转化为结构化的、可执行的指令 │
│ • 拆解目标和靶子 │
│ • 设计“训练线索”的生成逻辑 │
│ • 编写测试用例和评分标准 │
│ • 设计重试和写回机制 │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 第3层:Claude Code CLI │
│ 角色:主Agent + Agent Team,全自动执行 │
│ 动作:按照详细指令自主完成: │
│ • 生成训练线索 │
│ • 启动多个子Agent并行开发(核心能力) │
│ • 运行测试验证和差距分析 │
│ • 评估打分和决策重试 │
│ • 总结方法论并写回Skill │
└─────────────────────────────────────────────────────────┘
四、实战案例
文本风格转换
1.需求描述

2.执行结果

3.人工验收








