



一、京东缓存中间件架构
1、背景
在当今高并发、分布式的系统架构中,缓存已成为提升应用性能、降低数据库负载的核心组件。随着业务规模的扩大与系统复杂度的增加,缓存的使用和管理面临诸多挑战:部署模式多样、容灾策略不一、数据一致性保障困难等问题日益凸显。
在京东内部,大量业务系统依赖JIMDB作为缓存解决方案。然而,在实际使用与运维过程中,我们发现了以下几个普遍存在的痛点:
- 部署架构不统一:单集群单机房部署、单集群跨机房部署、多集群多机房部署。
- 容灾策略不统一:由于部署架构的差异,各业务团队需要自行制定和维护不同的故障预案。在发生大规模故障时,这些分散的预案难以被高效、协调地执行,容灾效果参差不齐,系统整体可用性面临挑战。
- 缺乏保障数据一致性的公共组件:缓存与持久化存储之间的数据一致性通常由各业务方自行实现。这些方案往往与业务逻辑深度耦合,实现复杂且难以复用。
为了解决上述问题,我们设计并实现了统一缓存中间件:DongDAL for KV(简称DongKV)。
- 标准化部署架构:收敛多种部署场景,提供统一的部署模式。
- 标准化容灾策略:实现集群级、机房级故障无需切换或一键切换。
- 统一缓存访问架构:提供标准化的缓存访问中间件,封装复杂性,降低业务方的使用与维护成本。
2、统一缓存高可用架构
当前JIMDB的容灾能力:
- 单个实例、物理机、交换机故障:属于日常高频故障场景。JIMDB具备自动故障发现与Failover能力。
- 机房故障:发生概率较低,但影响范围大。JIMDB虽支持主从倒换,但涉及大面积集群结构变更,效率与可靠性难以保障。
- 集群故障:偶发性强,危害极大。JIMDB缺乏标准化的容灾方案,依赖各业务自行定制切换或降级策略,风险较高。
针对机房故障和集群故障的场景遇到的问题,DongK提供了双JIMDB集群,双机房部署的标准化高可用架构。
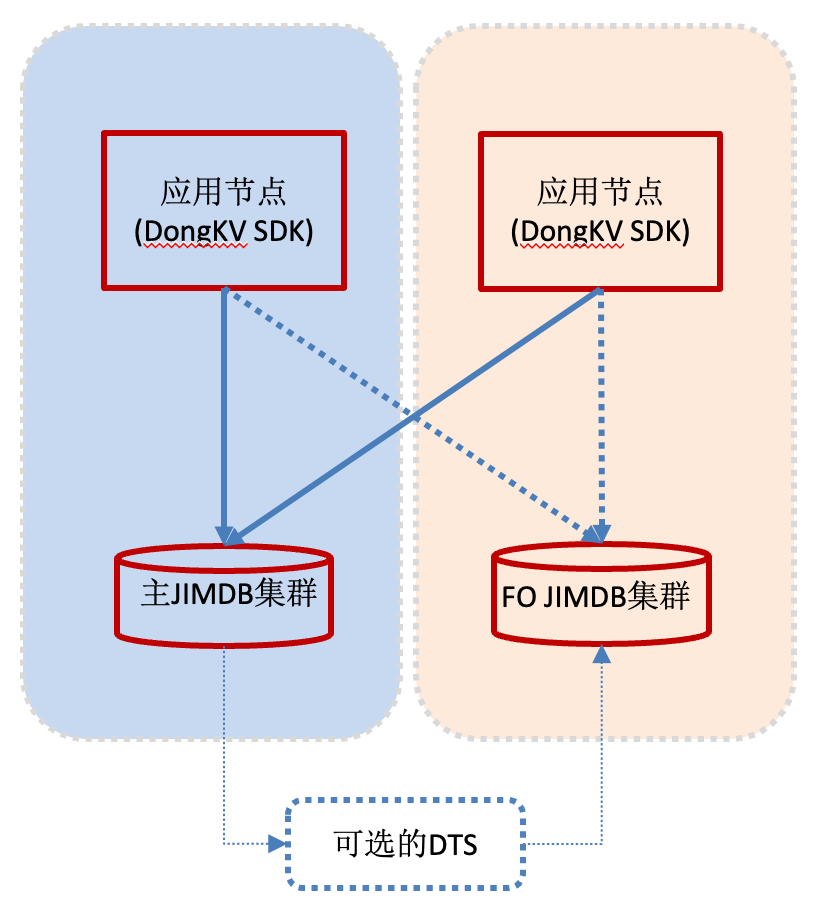
2.1、主备模式
在主备模式中,业务在每个机房各部署一个JIMDB集群,其中一个集群被定义为主集群,承载日常所有的读写流量;另一个集群作为备集群(Failover集群),处于热备状态。当主集群或主集群所在机房故障时,可以把应用访问JIMDB的流量一键切换到备集群。
需要注意的是,备集群因日常无写流量,无数据。为避免切换后大量请求因缓存未命中而“穿透”到底层数据库造成雪崩,用户可以主备集群之间通过DTS建立数据同步。这样,备集群能近乎实时地同步主集群的数据,确保切换时数据的“热度”,实现平滑切换。
主备模式适用于对缓存读写一致性要求极高的业务,例如库存预占、限购抢购等。
2.2、互备模式
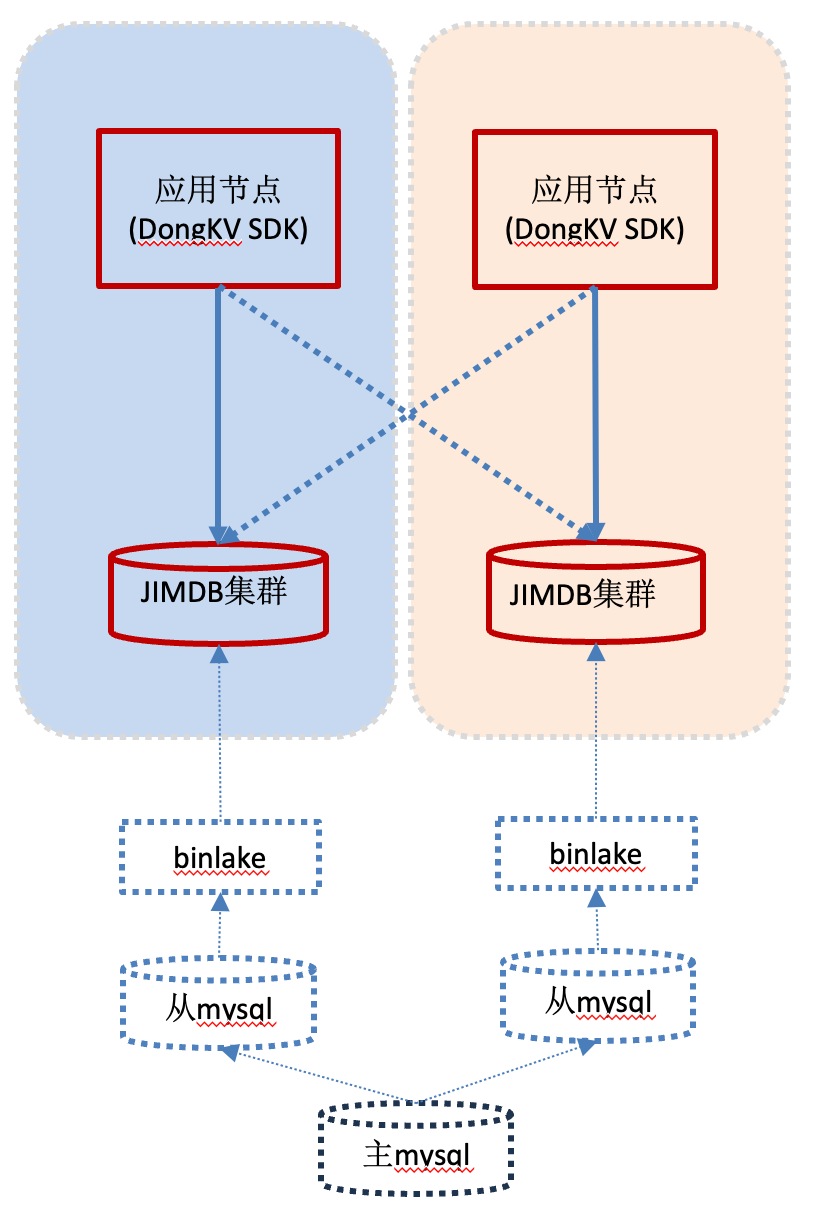
在互备模式中,应用也是在每个机房部署各一个JIMDB集群。与主备模式不同的是,这些集群日常各自承接本机房内应用的读写请求,形成“互为主备”的关系。若某个JIMDB集群(非整个机房)故障,管理员可通过DongKV管理端,一键将该集群的流量全部切换到另一个健康集群。若整个机房故障,部署在故障机房的应用可能不可用,但另一机房的应用与JIMDB集群组成的完整服务单元依然健壮,无需任何缓存流量切换即可继续提供服务,实现了真正的机房级容灾。
互备模式下的数据同步通常由业务自身的数据流驱动。以一个典型的商品读服务为例,其写数据链路(图中虚线框部分):应用将数据写入数据库,然后通过Binlake(数据同步中间件)将其“刷入”同机房的JIMDB集群。这样,每个机房都形成了一个写链路垂直封闭的单元,数据通过数据库的底层同步在机房之间实现最终一致。此写链路因业务而异,属于业务架构的一部分,不包含在DongKV中间件内。DongKV在此模式下的核心价值,是提供对双集群的智能路由与故障切换能力。
互备模式别适用于读写分离的业务,例如商品信息查询、优惠券查询。
3、统一持久化存储+缓存的解决方案
3.1、背景:数据一致性问题
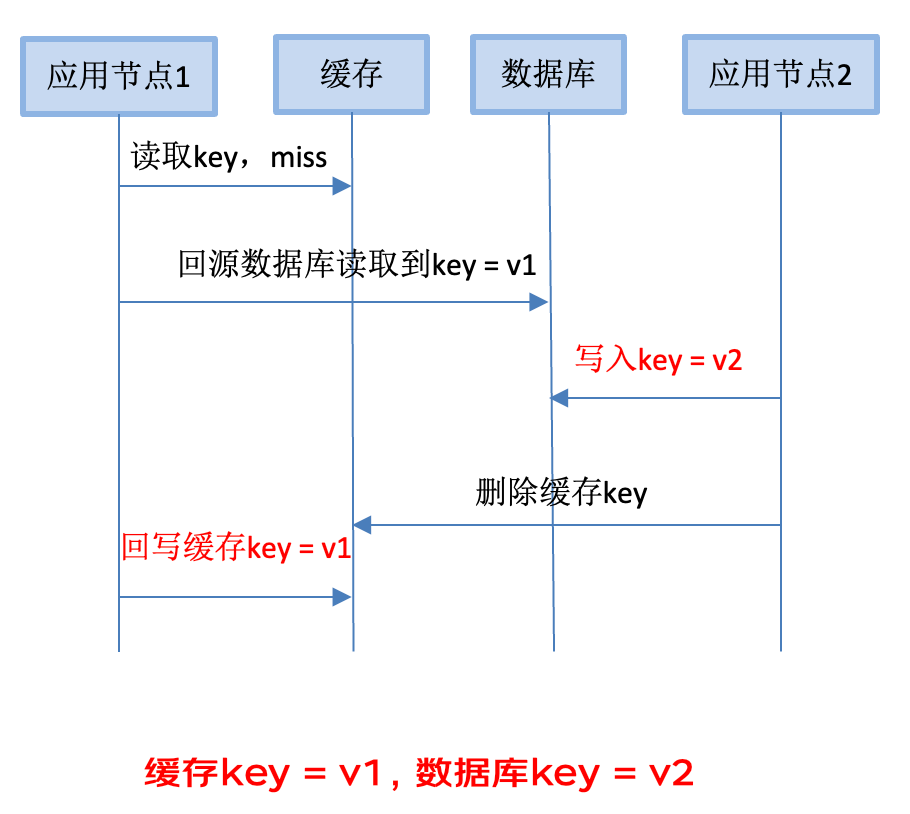
数据库在高并发场景下存在性能瓶颈。为决绝这一问题,应用架构需要引入缓存,存储频繁访问的热点数据,从而减少对数据库的直接调用。这样形成了数据库+缓存两级存储架构。然而,这种架构在高并发场景会出现数据一致性问题。
下面的示意图解释了这种不一致发生的原因。应用节点1访问缓存的key,没有读到数据,回源到数据库读取到key = v1。在回写缓存之前,应用节点1的工作线程被挂起。随后另一个应用节点2正好把数据库改成key=v2,然后删除缓存里的脏数据(虽然这时缓存还没有该key的数据)。之后应用节点1恢复执行,把key=1回写到缓存。这时候缓存的key=v1,数据库的key=v2,从而造成数据不一致。
3.2、痛点
重复建设:业界有一些关于持久化存储+缓存的解决方案,如简单粗暴的延迟双删,如Facebook的基于租约的最终一致性方案。业务在各自的系统里实现这些方案,导致技术资产无法沉淀和复用,形成“重复造轮子”的局面,且方案质量参差不齐。
代码耦合:上述一致性逻辑通常直接嵌入在业务代码中,与核心的业务流程紧密耦合。这不仅使得业务代码变得冗长、复杂,更导致一致性策略难以独立演进或优化,任何改动都可能引发风险。
代码复杂度高:要实现一个完善、健壮的数据一致性方案,实现复杂度极高。许多业务因难以驾驭此复杂度,采取了规避策略,直接将缓存作为数据库使用。这种做法虽然暂时绕开了数据一致性问题,但付出了高昂的资源成本,并因缓存数据的非持久化特性而引入了巨大的数据丢失风险。
3.3、解决方案
针对上述痛点,DongKV的核心设计思想是将数据一致性的复杂逻辑从业务代码中下沉到缓存中间件层,为业务提供标准化的访问接口与可配置的一致性策略。目前,DongKV主要对两种典型业务场景提供支持。
3.3.1、数据库+JIMDB的强一致场景
以订单状态为例,应用了更新订单状态,后续读取必须反映最新状态。例如,用户支付完成后查询订单,DongKV能严格保证后续的读操作返回最新的“已支付”的状态。
DongKV强一致性方案基于“版本-租约-状态”模型,通过数据库与缓存的协同机制保障数据一致性。利用版本控制实现数据同步,租约机制规避脏写,状态机驱动流程,最终在分布式场景下兼顾一致性与可用性。
(1) 核心设计
- 版本号(Version):数据每次更新时版本号递增,作为数据变更的唯一标识。
- 租约(Lease):缓存节点通过租约机制临时独占数据写入权,租约过期后需续期或释放。
- 状态标记(State):数据在缓存中的状态分为有效(Valid)、过期(Expired)、待更新(Updating)三种,驱动一致性逻辑。
(2)协同机制
- 写操作:数据库更新后版本号+1,同步失效缓存;持有租约的节点负责将新数据回填缓存。
- 读操作:若缓存数据状态为有效且版本匹配,直接返回;若过期或版本落后,触发同步或阻塞等待更新。
- 租约管理:租约超时后自动释放,防止节点故障导致数据锁死;续期需验证版本号,避免脏写。
此外,DongKV还提供了流量降级到数据库的能力。即使在JIMDB集群故障的情况下,依然保障业务的可用性。
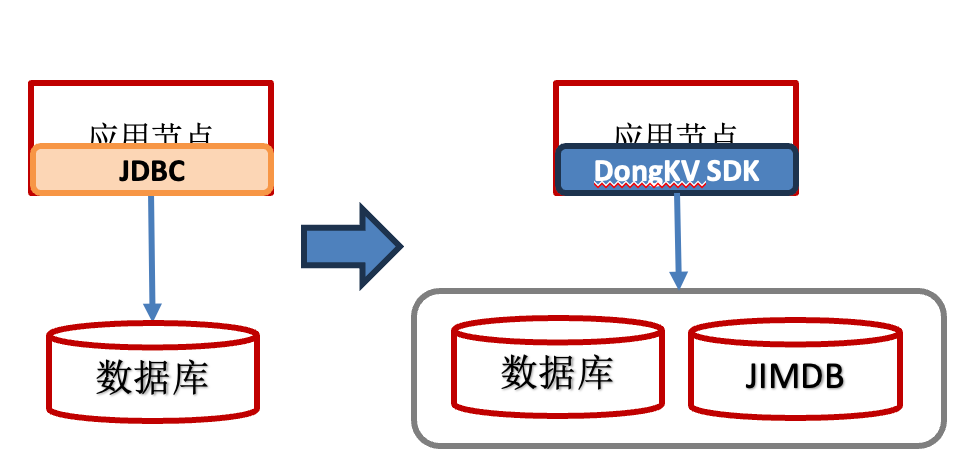
3.3.2、JIMKV+JIMDB的最终一致性场景
如商品读服务,访问量大,性能要求高,但是接受读取到一定过期的数据。针对这个场景,DongKV提供了冷热分层存储能力。全量数据放在JIMKV(持久化存储),热数据放JIMDB。用低成本存储承载全量数据,仅将最热的数据子集保留在内存中,实现成本与性能的平衡。JIMKV与JIMDB均为KV接口,存量业务迁移或接入此架构的改造成本很小。
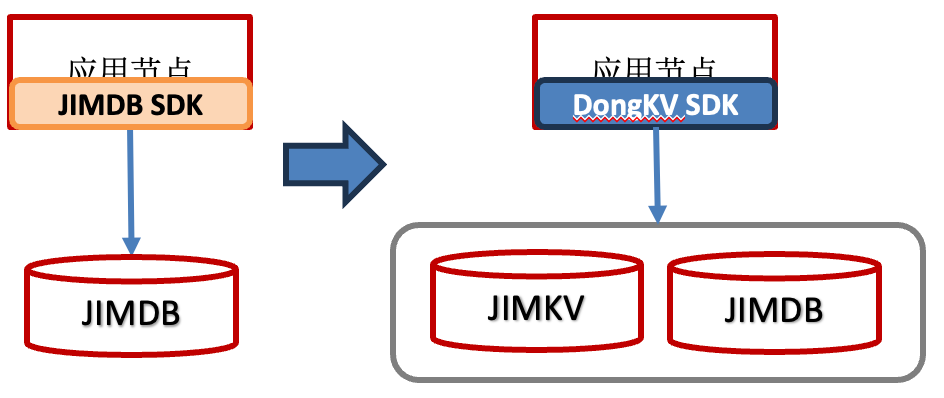
二、JIMDB内核新特性
1、大热key的自动识别与处置
大热key的自动识别与处置是JIMDB的一个自研特性。
1.1、背景
大热key访问是JIMDB线上故障的第一大根因。发生大热key访问的具体表现是:CPU资源耗尽,拒绝服务;带宽打满,数据积压在内存导致容器OOM。
1.2、什么是大热key
这里以超市收银员的工作来做个类比。现在我们网上购物比较多,很久以前我经常会去一家超市线下购物。这个超市只有一个收银员,需要做商品扫码、计算总额、把商品打包到购物袋的事情。这个收银员非常熟练,即便在排队的高峰期,我们也能在几分钟内完成结账。有一天我排了10分钟,发现队伍没怎么动。上前看了眼,每个人购物车里都是满满的商品,据说是活动打折。收银员忙的不亦乐乎,估计最少还得等半小时,我只好放下东西走了,默默走了。
和这个超市收银员一样,JIMDB是单线程处理请求。如果遇到一个几千个元素大key访问,JIMDB需要遍历几千次,序列化数据,最后将这些元素拷贝到输出缓冲区等待发送给客户端,处理耗时长。只是少数这样的大key访问,影响还好,一旦发生了热点访问,如同上面在超市排队的场景,排在大key后面的请求长时间得不到处理,最后全部超时。
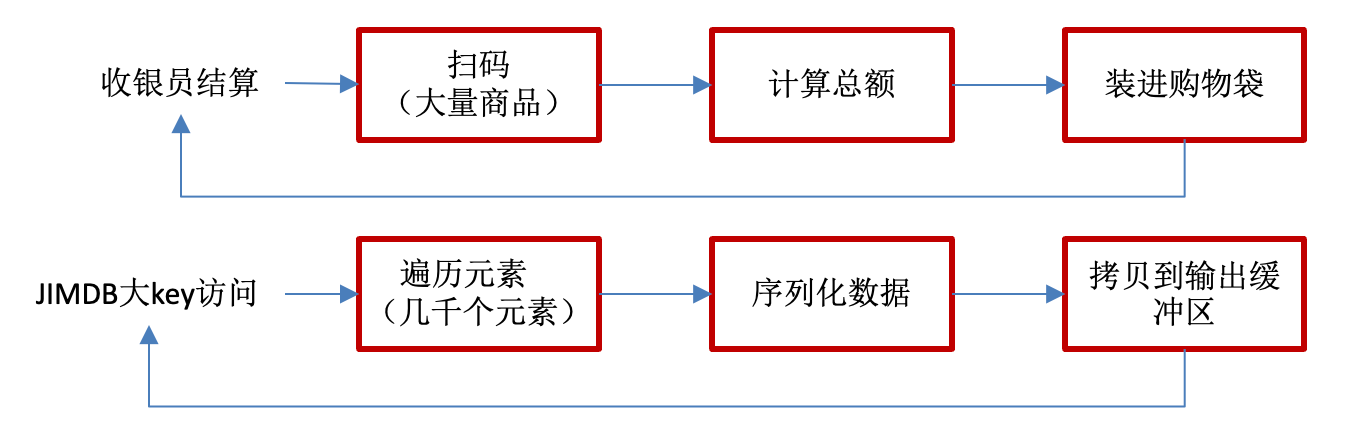
回到大热key的概念,其实就是大key发生热点访问。JIMDB提出了以资源影响为标准定义大热key:一个针对特定Key的、与具体命令和参数强相关的操作,因其处理的数据量与执行频次的叠加效应,导致服务端CPU或网络带宽被耗尽的事件。
1.3、大热key自动识别
确立了以资源影响为核心的“大热Key”定义后,JIMDB为此设计了一套精密的、多层次的识别策略。该引擎并非简单的阈值监控,而是一个结合了实时计算、静态预判和机器学习预测的智能感知系统。
为了最大限度地降低识别过程本身对服务性能的影响,JIMDB的识别引擎遵循一个“由简入繁、快速失败”的瀑布式检测原则。当一个命令被执行时,服务端会依次进行以下三个层面的检查,一旦满足任一条件,即判定为大热Key并中止后续步骤:
- 带宽瓶颈检测: 响应大小 * ops >= 网络带宽 * 70%。
- 集合大小瓶颈检测: 若未触及带宽瓶颈,则对集合类型进行静态大小检查。
- CPU算力瓶颈检测: 最后,对命令进行基于预测模型的CPU负载分析。结合了元素个数、响应大小和ops,利用线上性能数据,使用机器学习的方法,来预测该请求在多少个ops下可能造成CPU瓶颈的。
1.4、大热key自动处置
在自动识别到大热key之后,JIMDB在内核还提供了从服务端到客户端、从自动处理到人工干预多种应急机制。
- 服务端缓存:解决大热key访问CPU打满的问题
识别到一个大热key操作之后,响应会被缓存到服务端,后续的请求不再去做遍历元素、序列化、内存拷贝的操作,直接使用服务端的大热key缓存,缓解CPU压力。
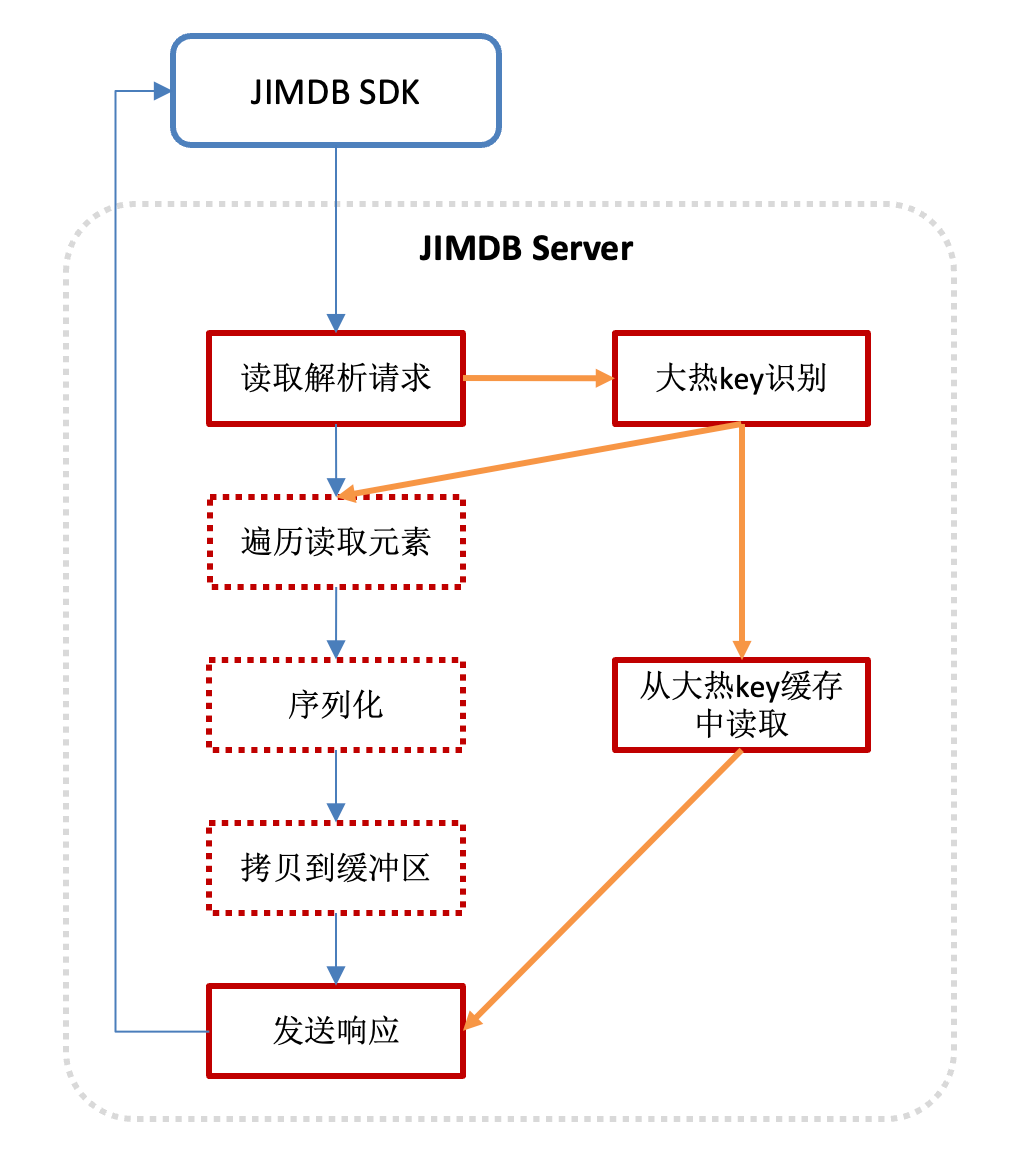
- 客户端缓存:解决大热key访问带宽瓶颈问题
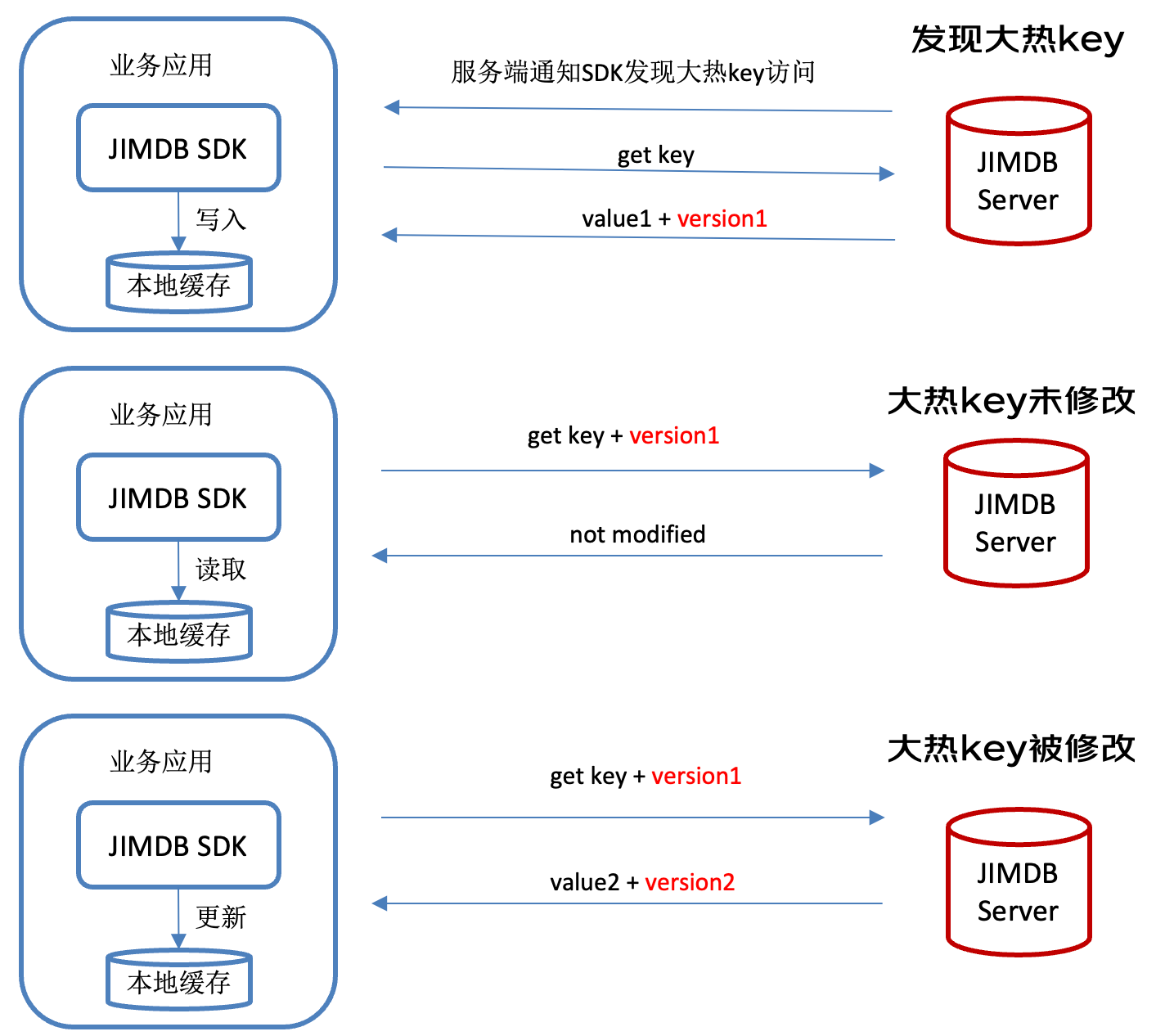
客户端缓存解决了大热key访问带宽瓶颈问题,并且可以保障保障客户端缓存与服务端数据的一致性。每个大热key缓存项都带有一个版本号。一旦该key被修改,JIMDB会同步修改缓存项的value和version。
当服务端发现大热key访问时,会生成本地缓存,并通知客户端。客户端访问该key时,服务端会返回该key的value和version。客户端下次访问会带着key和version去询问服务端。如果该key没有修改,那么服务端只是返回该key无变更,不会返回value。如果该key被修改了,服务端返回value和新的version。在key很少变更的情况,服务端几乎不用返回整个value。这样既较少了带宽占用,又保障了缓存数据的一致性。
- 服务端熔断
考虑到可能存在大热key识别未覆盖的情况,JIMDB服务端提供了key级别和命令级别的熔断能力。在发生未被自动识别到的大热key风险时,可以人工介入熔断该风险访问,避免影响同一个实例的其他请求。
目前这个版本已经覆盖了线上超60%的JIMDB集群,日均防御超千次大热key风险访问。该版本的集群在线上没有发生过大热key访问导致的故障。
2、异步IO多线程
异步IO多线程是开源社区引入的新特性。
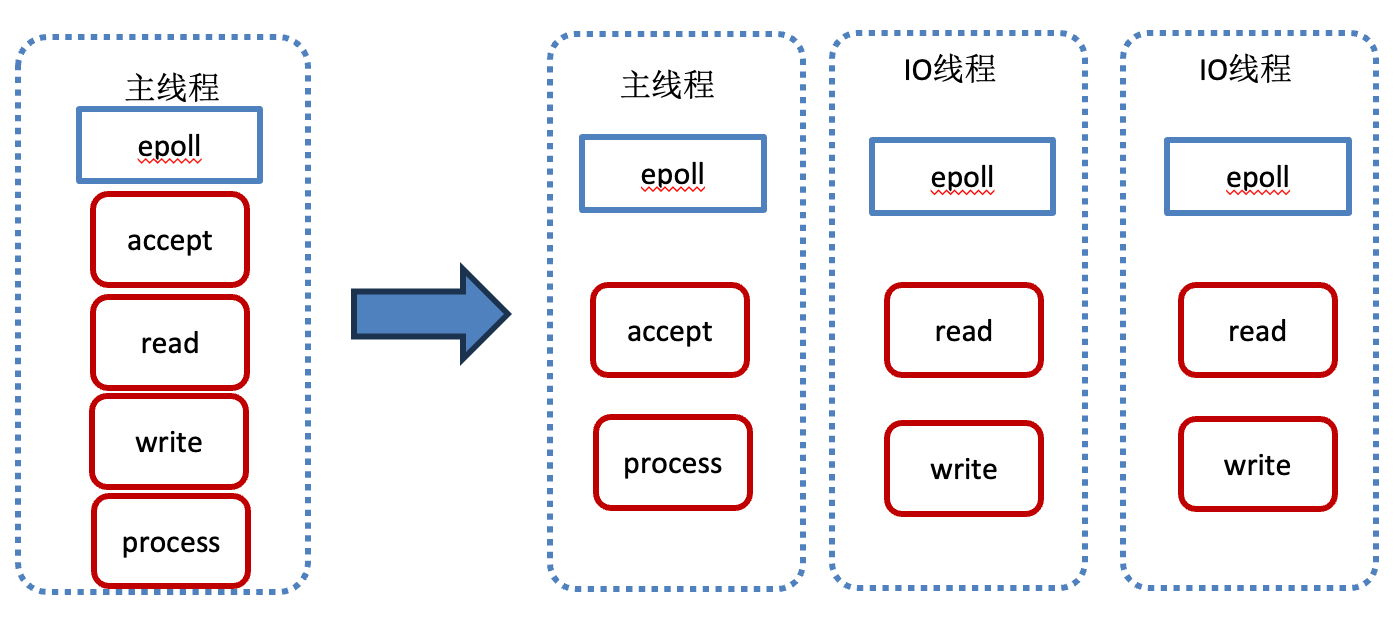
目前线上JIMDB内核绝大多数是基于Redis2.8基础二次开发的,这是一个单Reactor单线程的模型。
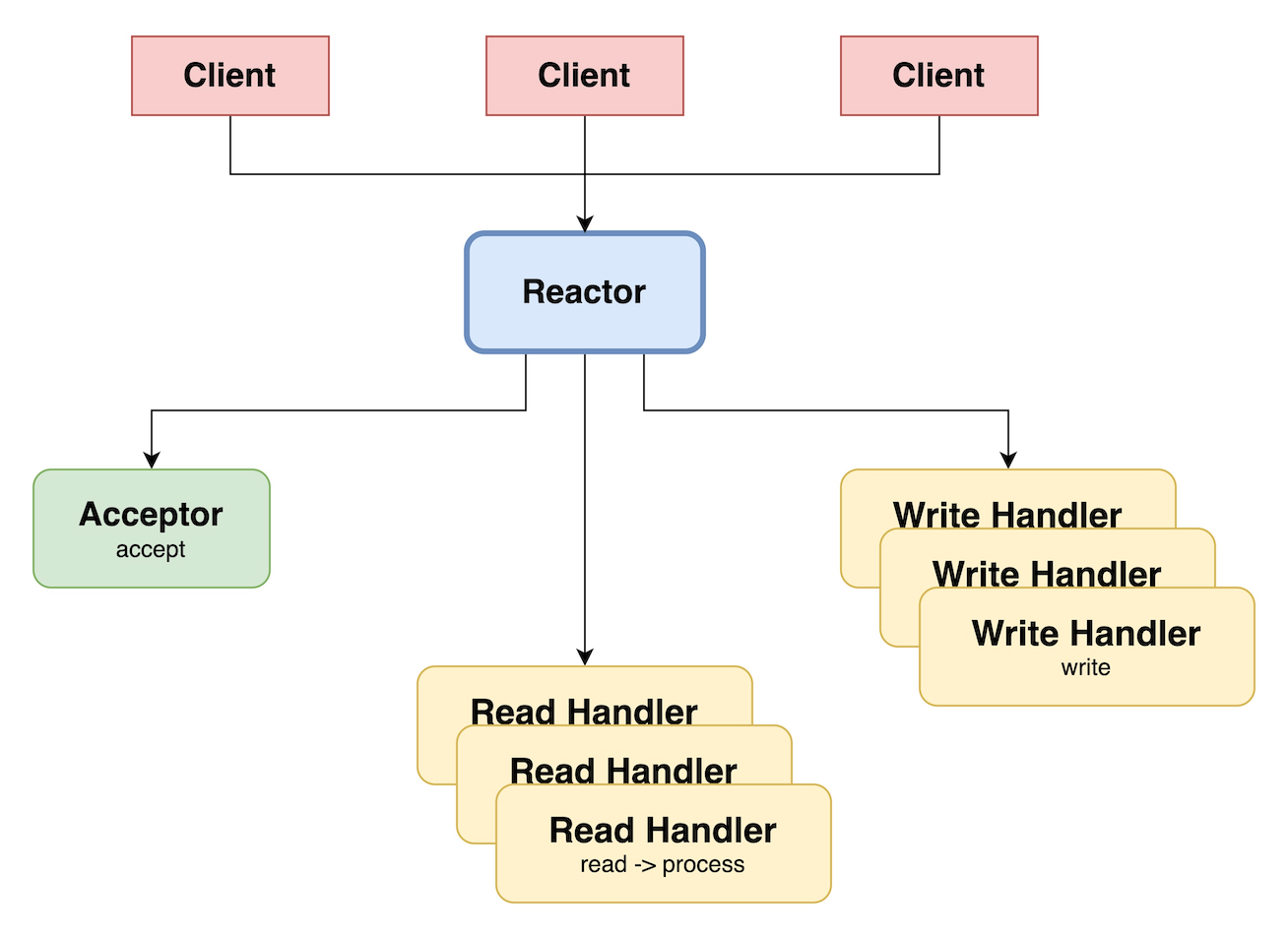
单线程里唯一一个epoll就是这里的Reactor,负责接受连接、网络读写操作和命令处理的工作。单Reactor单线程的优点是无锁,命令执行速度快。缺点也很明显,性能上限受制于单核CPU。
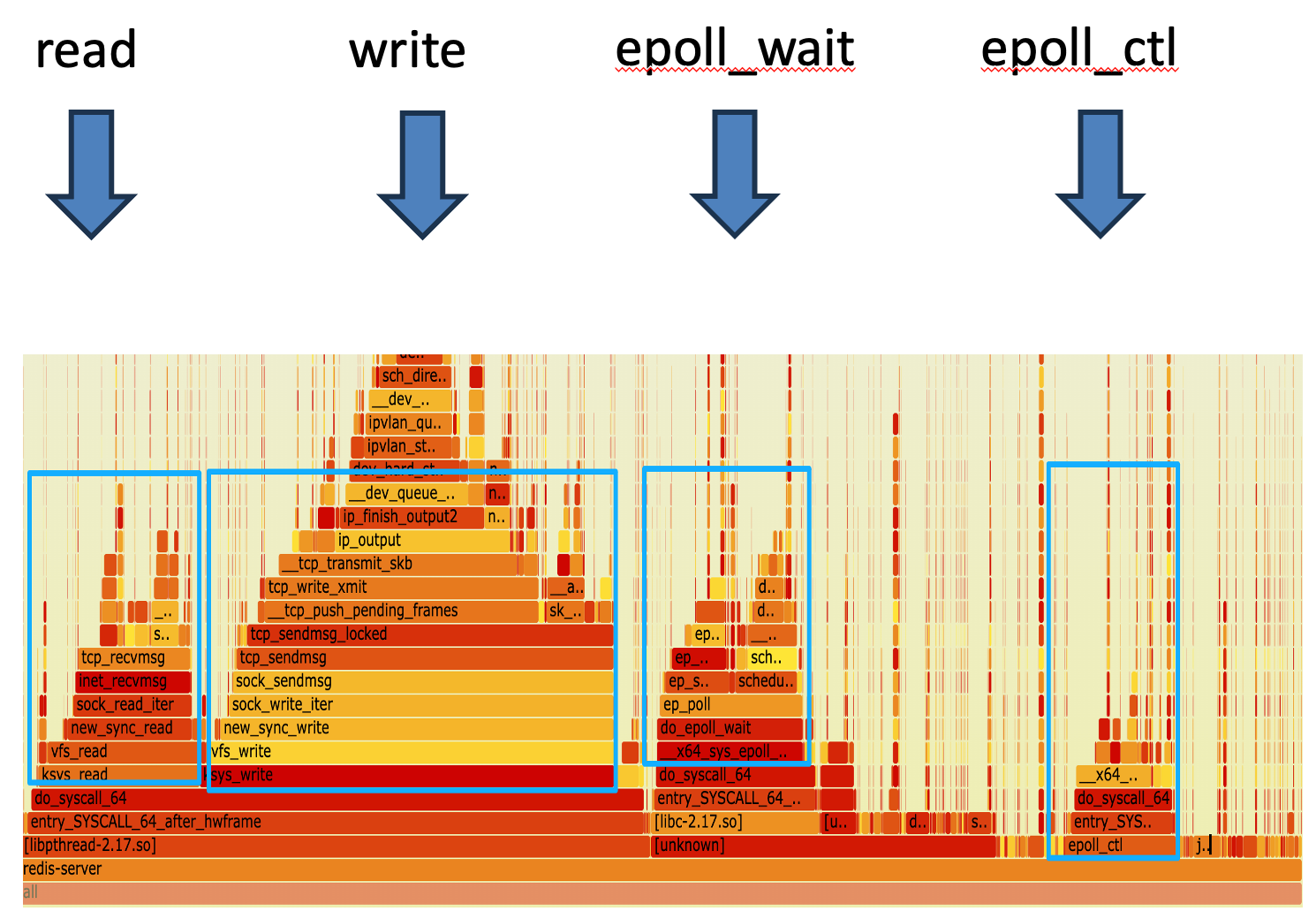
通过火焰图我们可以看出,单线程的JIMDB只有少部分CPU在处理命令,大多数CPU时间花费在网络IO上。
异步IO多线程就是来解决这个问题的,将原来的单Reactor单线程,变成了多Reactor主线程+IO多线程模式,将网络读写的开销从主线程卸载到IO线程。
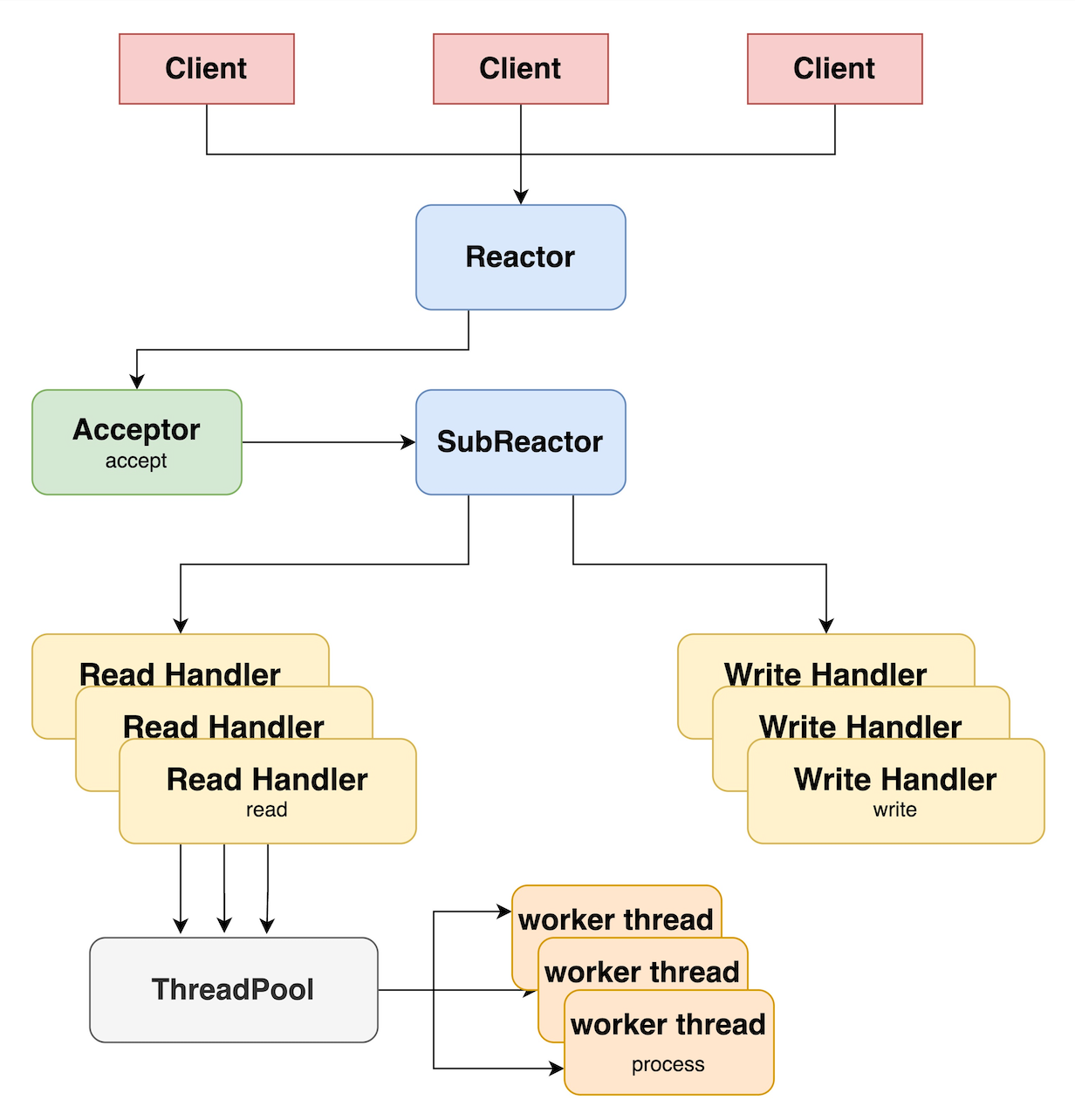
主线程的epoll就是这里的mainReactor,负责连接的创建。创建好连接后,主线程会将连接分配给一IO线程,并注册到IO线程的epoll上。每个IO线程的epoll就是subReactor,负责网络数据读写。在多Reactor模型中,subReactor读取到请求后,将其提交到线程池。线程池分配给一个worker线程处理命令的解析、执行和结果序列化工作。这里的worker线程就是我们的主线程。每个IO线程将读取到的数据异步通知主线程处理。这个主线程就是多Reactor模型的工作线程池。因为主线程只有一个,所以所有命令处理依然可以在无锁的情况快速执行,同时主线程也不再承担网络读写的开销。
通过引入异步IO与多线程优化技术,JIMDB单实例在4核4线程配置下的OPS(每秒操作数)性能较原单线程模式提升超过150%。这一改进的核心价值在于通过提升CPU利用率实现资源节约:在单线程架构下,每个实例无论分配多少内存,仅能占用单核CPU算力,导致服务器整体CPU利用率长期偏低。而单核处理能力存在物理上限,过去为应对高并发读流量,许多集群不得不部署多个副本分担压力。升级新版本后,单实例可充分调用多核计算资源,使得相同流量压力下副本数量显著减少,从而降低内存资源占用总量。与此同时,新版本通过利用闲置CPU核心,使服务器整体CPU利用率得到有效提升。
三、总结
京东零售数据库存储团队通过构建DongKV统一缓存中间件与优化JIMDB内核,打造了高可用、高性能的分布式缓存体系。标准化双集群架构(主备/互备模式),实现了秒级容灾切换与机房级故障自愈,显著提升了系统可用性。在数据一致性方面,基于“版本-租约-状态”模型,为数据库+缓存场景提供了强一致与最终一致两种标准化解决方案,有效解决了数据不一致问题。内核层面,通过大热key自动识别与处置机制,将大热key引发的线上故障率降低60%以上;同时,异步IO多线程技术使单实例性能提升超过150%,显著提升了CPU利用率并降低了资源成本。






