




背景介绍
业务场景
促销优惠券数据是索引重要组成部分,优惠券数据存储的信息为一个优惠券batchId下绑定一批选品数据(如sku,类目(cid),店铺(vender)等),在对数据进行处理时需要将优惠券中台下发的选品数据按照优惠券batchId进行聚合,构建优惠券索引,下发到搜索引擎中进行商品召回,由于其结构化特性不能像商品数据一样进行统一处理。
•产品形态
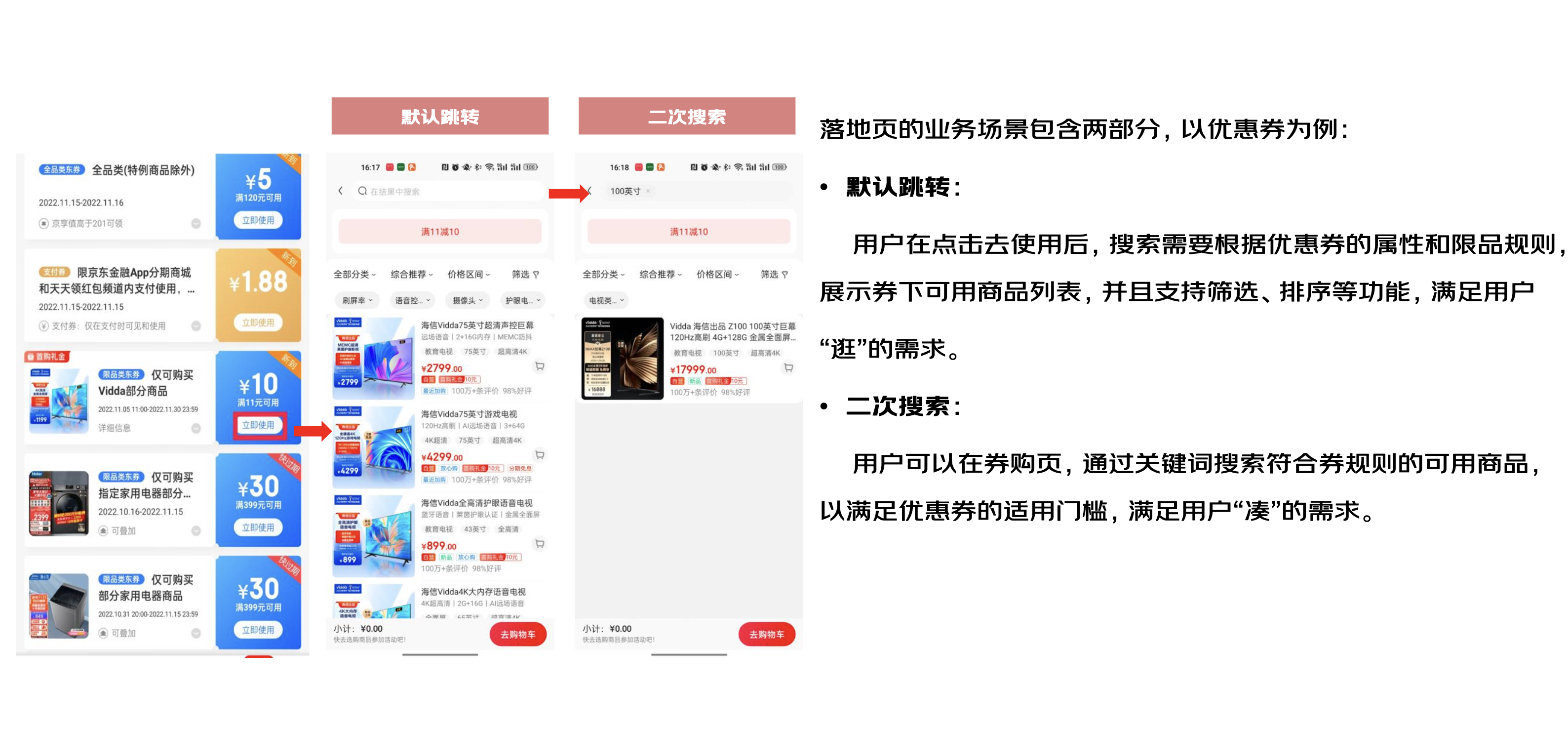
•索引结构
业务需求及痛点
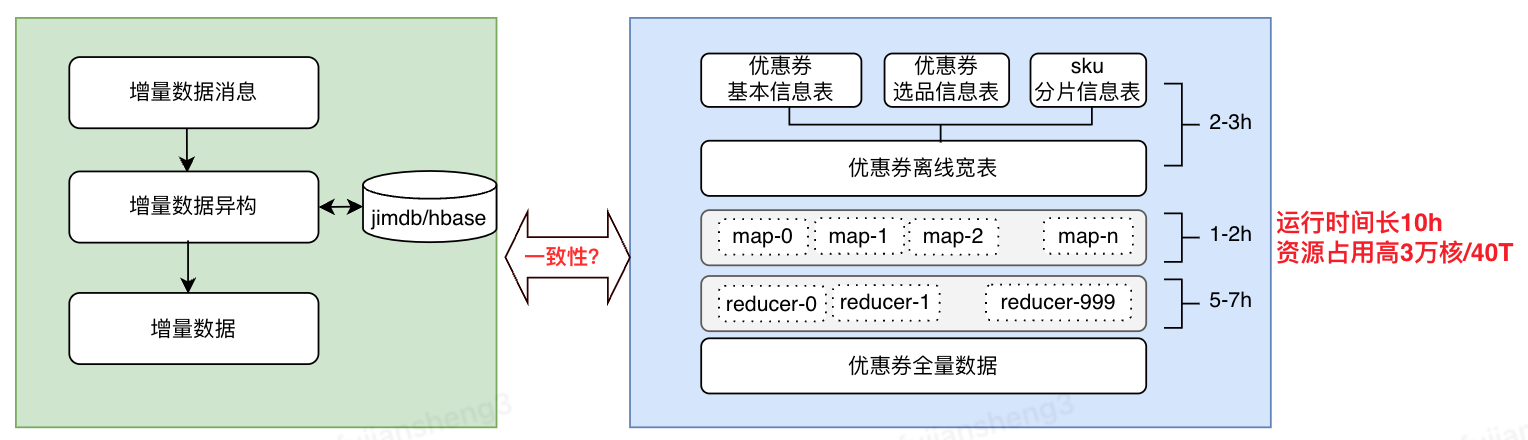
•痛点一,全量两套架构,资源消耗高
1.增量全量两套架构,容易引起数据不一致
2.全量需要进行宽表join及数据聚合等操作,运行时间长10h,资源消耗高3万核/40T,严重阻碍了业务迭代速度
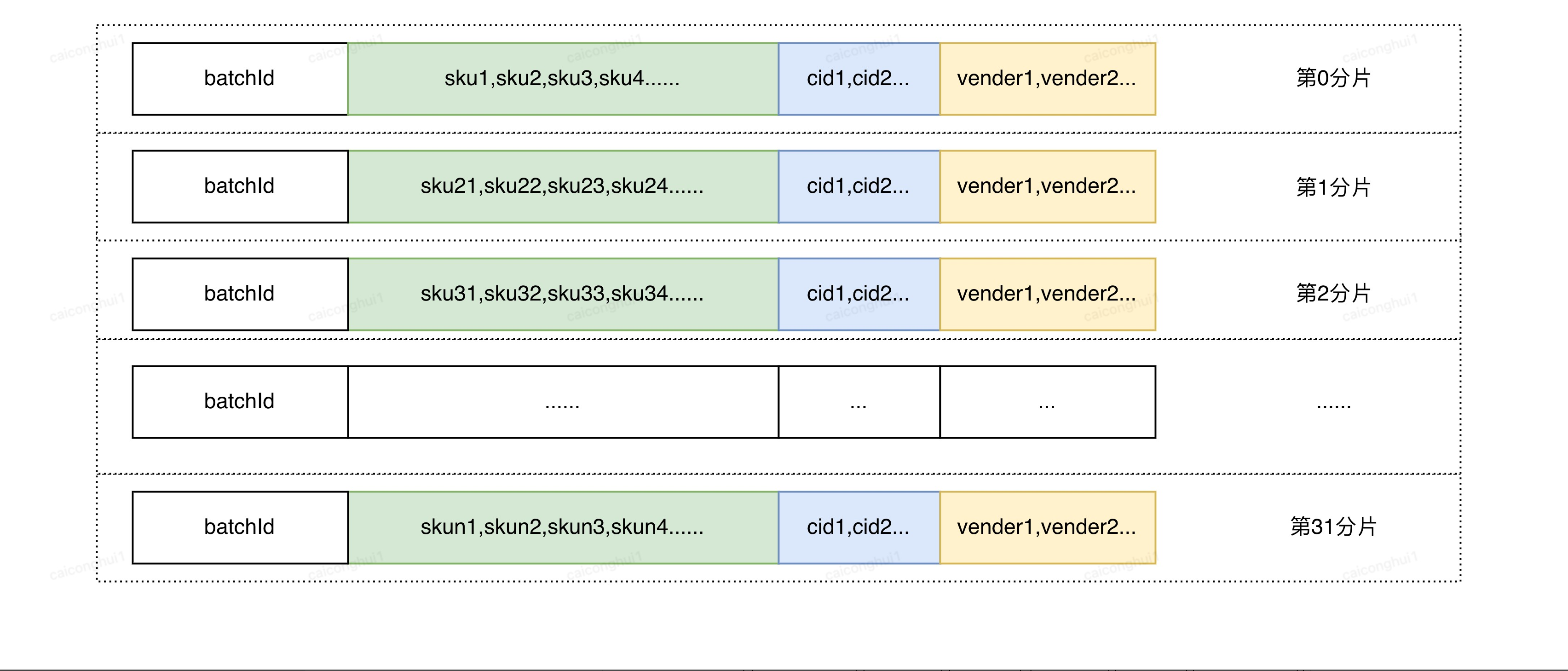
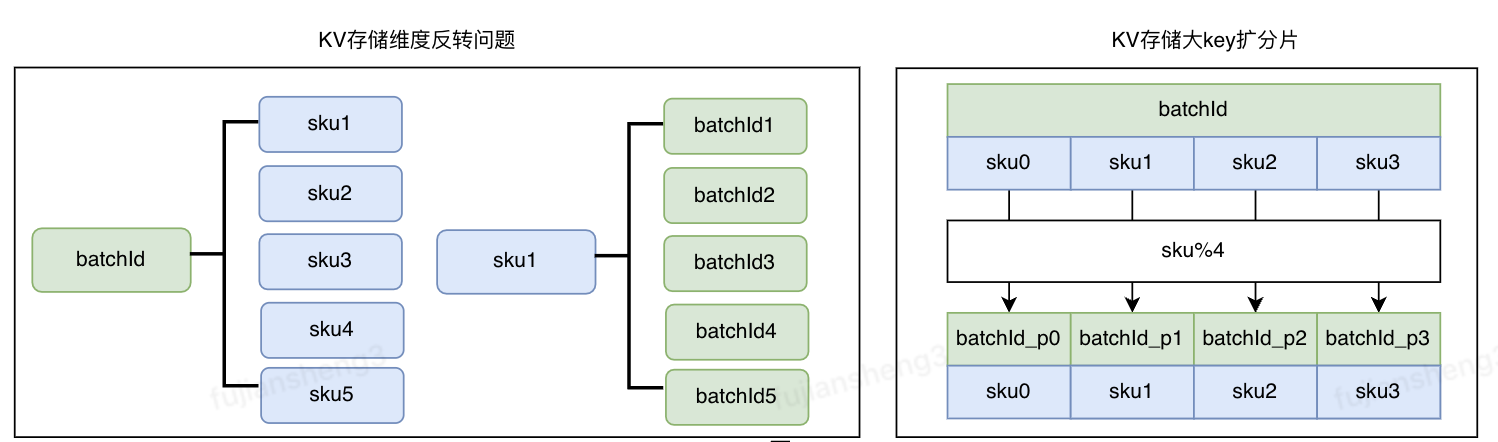
•痛点二,核心存储为kv引擎,容易引起数据倾斜及数据不一致,丢数及延迟
1.核心存储为kv引擎,需要面临维度反转及扩分片问题,容易引起数据不一致
2. 优惠券数据倾斜,大key问题
优惠券个体之间选品数差异较大,以下为双十一期间优惠券绑定选品数量分布情况,优惠券总量级在200w左右,双十一时满200-20优惠券选品数可达达到6亿,选品总量级在百亿以上,数据倾斜问题严重
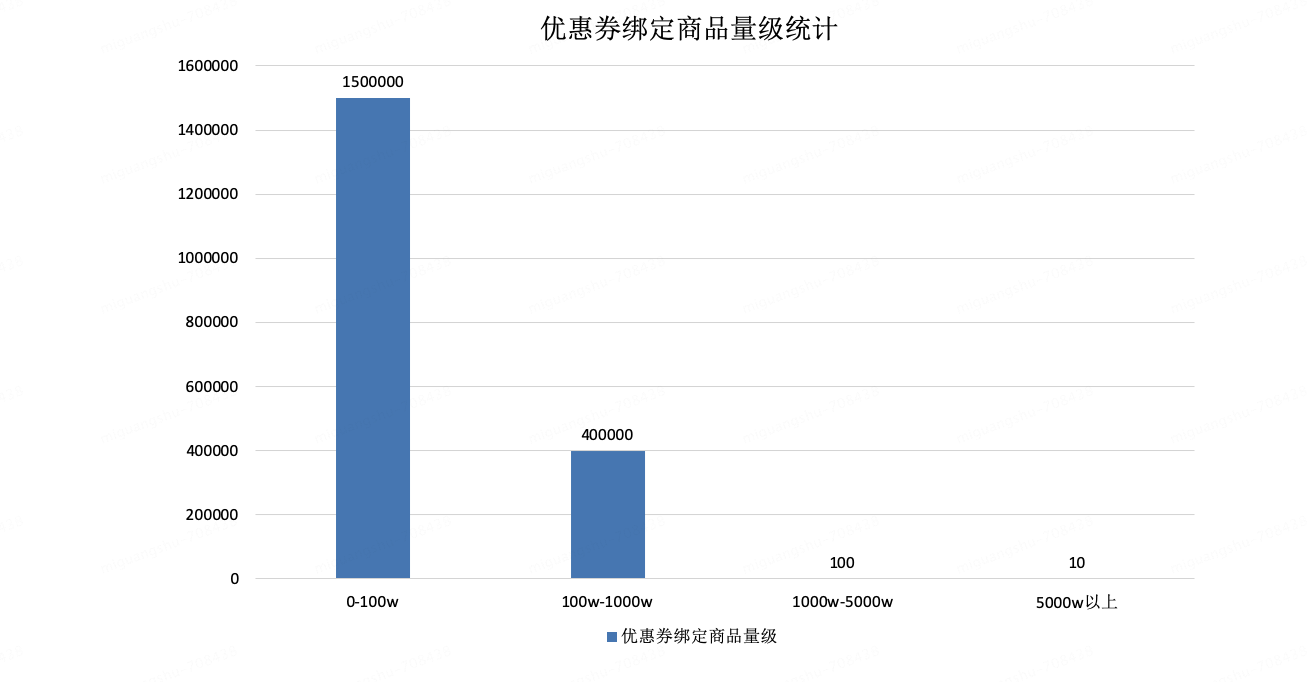
大促单个优惠券最高达到 6 亿 sku+ 选品存在多方面问题:
1.超大券在出仓时容易由于网络波动造成的超时从而导致出仓失败,单分片sku达到三百万sku,单个券大小几十M
2.在持久化时通过 jimdb 与 增量化数据处理服务进行数据交互,单分片数据大小过大造成了 jimdb 大 key,从而产生服务抖动;
3.券促增量微批全数据出仓导致在线端磁盘存储压力过大;
4.单个券促全量出仓方案已经不能满足业务方对于数据延迟需求。
架构演进
流批架构统一
技术选型
问题:KV存储是否合适?
kv存储及明细存储结构对比
Apache Doris 已在搜推登月数据分析场景中解决了大规模实时数据查询的问题,虽然OLAP引擎主要用于报表分析,但其优异的计算能力表现让我们思考是否索引数据处理也能使用Doris引擎来解决。在索引数据处理的场景中,Doris的一些优异特性比如高吞吐,低延迟,可灵活水平线性扩容,行列混存等技术与我们对底层存储引擎的需求极为契合。于是,我们考虑将Doris引擎作为索引数据处理的核心底座。
当数据存储在OLAP系统中时,我们直接利用Doris表来存储明细数据,将批量的查询结果直接返回到应用端,在应用端进行数据聚合。KV存储引擎的特点是可以在短时间内处理众多的点查询请求,可以实现百万级以上数据处理,但是每个查询返回的数据量不宜过大。 Doris引擎的特点是批量处理海量数据的能力比较强,虽然高qps的支持不如kv存储系统那么高,但是每次查询的结果可以返回大量的数据。我们处理数据的场景,目标是在指定时间内,完成海量数据的加工处理,比如1分钟之内需要处理多少个优惠券数据,因此,我们就可以利用doris引擎强大的数据批处理能力,进行微批查询,一次微批查询可以等价于kv系统的1000次点查, 从而达到和kv系统在同样时间内处理同样的数据量。
| 存储引擎 | 存储结构 | 优点 | 缺点 | 一次查询返回数据量 |
| jimdb | list | ·访问速度快qps高 | ·value不宜过大(jimdb建议不超过5000) ·业务层面临频繁扩分片问题 ·没有导出及snapshot功能 | 5000 |
| doris | 列式存储 | ·存储量级大 ·水平扩容方便 ·单次请求返回数据量高(可达千万级) ·导入导出方便 ·snapshot支持 | ·qps相对kv较低 | 500万 |
方案设计
我们将异构模块分为三部分,第一部分数据适配模块,由于数据来源有多种,实时topic及离线hive表,我们将消息适配后导入到doris中,第二部分为入仓模块,利用doris的sequence列保证消息时序,入仓成功后发出消息,通知下游发生更新的优惠券batchId,第三部分为聚合出仓模块,当接收到优惠券更新消息后,按优惠券batchId进行聚合出仓。
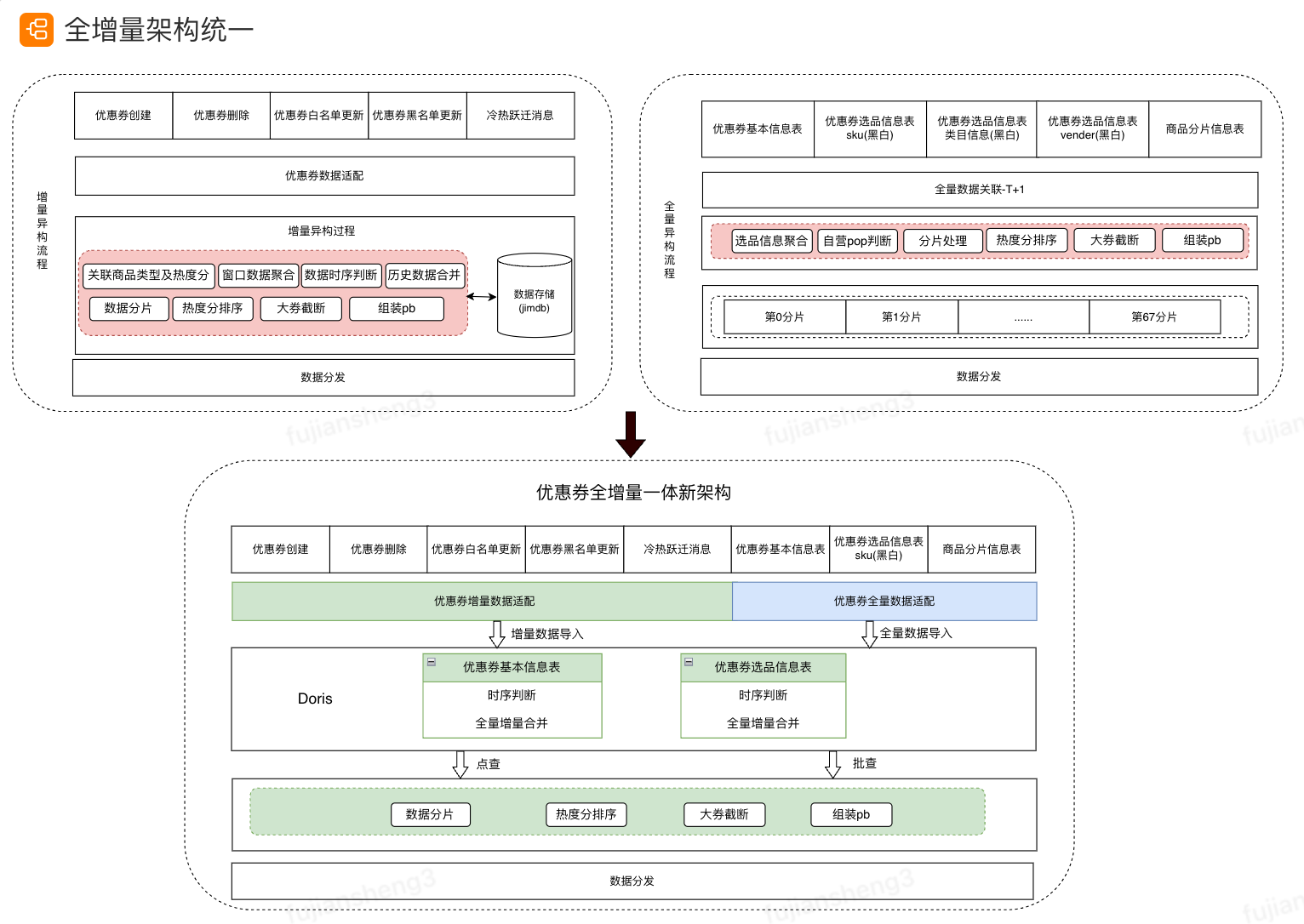
全增量统一: 聚合出仓模块有两种部署模式,一种为点查方式,部署方式为flink通过流处理方式进行增量数据更新,一种方式为批查,用于全量数据制备,部署方式为worker方式,代码复用,实现了全量与增量的统一。
优惠券流批一体重构收益
1.接入效率提升50%
2.统一全量与增量数据到Doris引擎,解决数据不一致问题;
3.全量建库时长从10h->2h,全量数据时效从T+1->小时级,每天可以节省大数据离线计算资源约3万核*小时(该数据由大数据平台资产分析与治理的离线账单获取);
4.提升用户体验,优惠券单分片截断数从30万->不截断;
5.数据均衡,解决热点更新问题。
抽象通用架构,赋能其他应用
1.LBS同城推荐底池重构
2.订单搜索数据重构
稳定性建设
方案设计
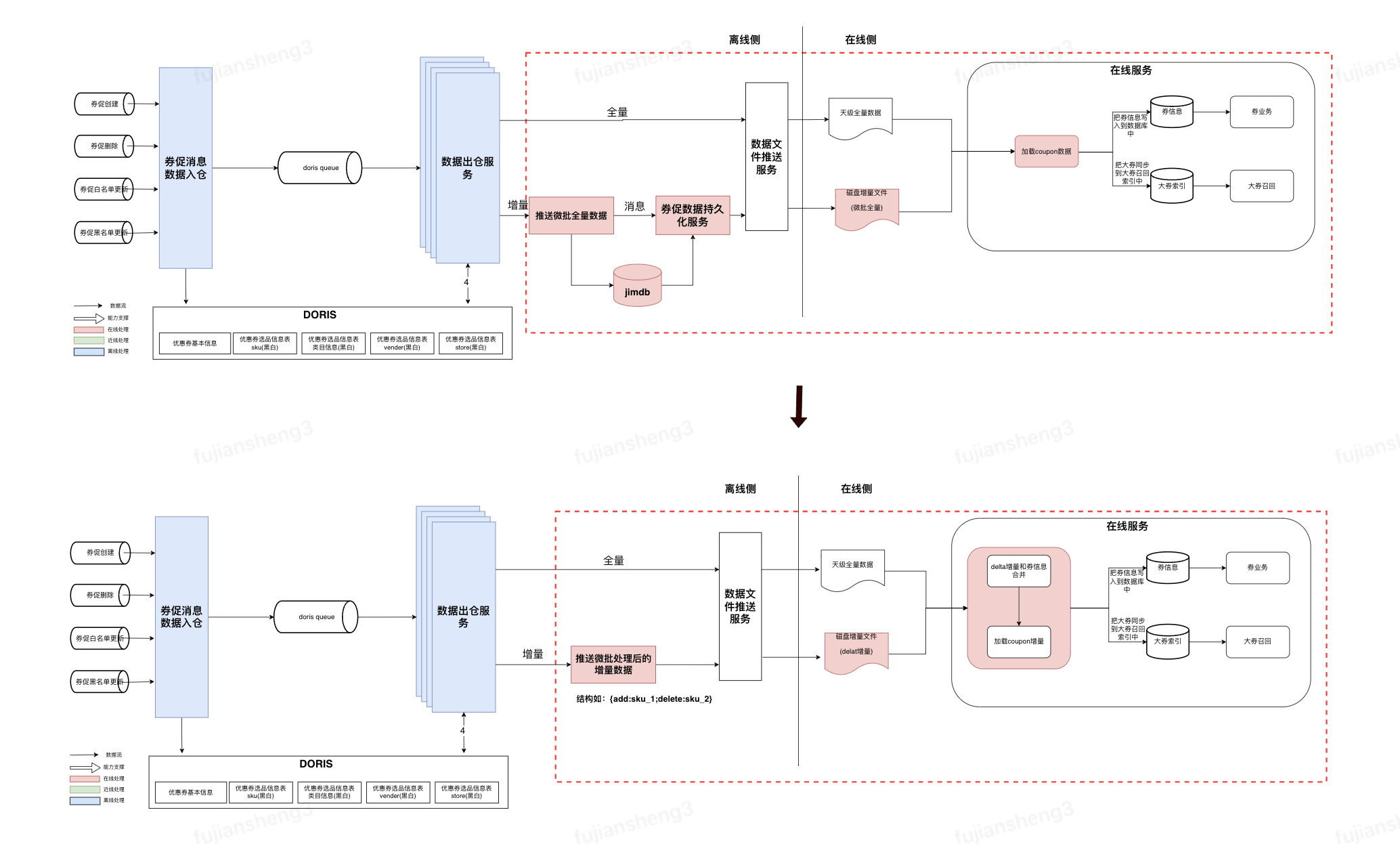
•架构改造
◦简化券促出仓链路,去除增量阶段与其他服务交互,券数据出仓后直接进行持久化到cfs;
◦调整 jvm 参数并新增背压及内存控制能力,保障全增量出仓服务稳定性;
◦增量化出仓对超大券单独存储,一定时间内只保留同一个券下最新数据将其他超大券历史数据删除;
◦支持指定部分券促id降低更新频率。
上线成果
1.os、ps券促迁移新架构去除Hadoop及HIVE依赖, 全量出仓整体速度提升约 96%(27h->1h);
2.解决了618期间大券难产问题;
3.去除券促出仓对多个外部服务依赖,缩短了数据链路,提升了服务稳定性;
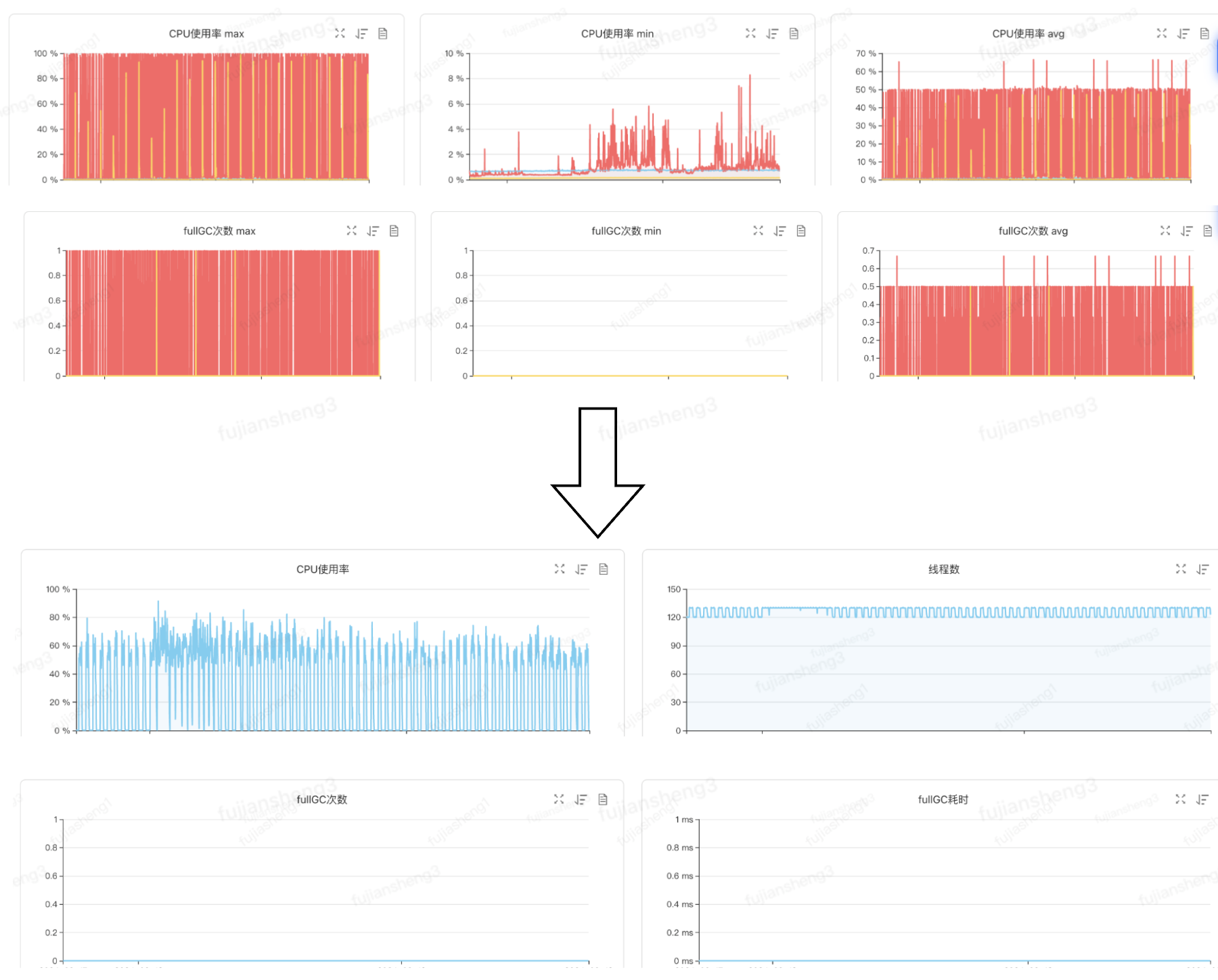
4.服务单机负载降低,不再有fullgc出现;
5.在线端磁盘占用大幅降低。
调整jvm参数&新增背压及内存控制
机器负载优化前后对比:
券促时效性优化
券促出仓增量化改造
随着业务发展业务侧提出了更高时效性要求,微批全量出仓方案已经无法满足业务发展需求,同时在线端磁盘使用问题也急需解决,需要升级为纯流式增量处理方式。
方案概述:
1.数据结构及消息消费调整,适配增量化处理能力;
2.出仓调整增量数据推送方式,推送coupon对应skuList时只推送变动的sku;
3.在线端基于推送信息动态更新coupon与skuList关系
上线成果
1.资源方面
彻底解决在线端磁盘存储问题,增量化降低存储95%以上
2.性能方面
增量化处理耗时大幅减少,双十二期间减少处理耗时96%以上
消息延迟大幅降低,平均几十秒内处理完成,超大券增量更新延迟降低97%
3.稳定性方面
机器负载压力降低80%以上,稳定性大幅提升
通过增量化查询极大降低了对底层doris压力
机器负载压力对比
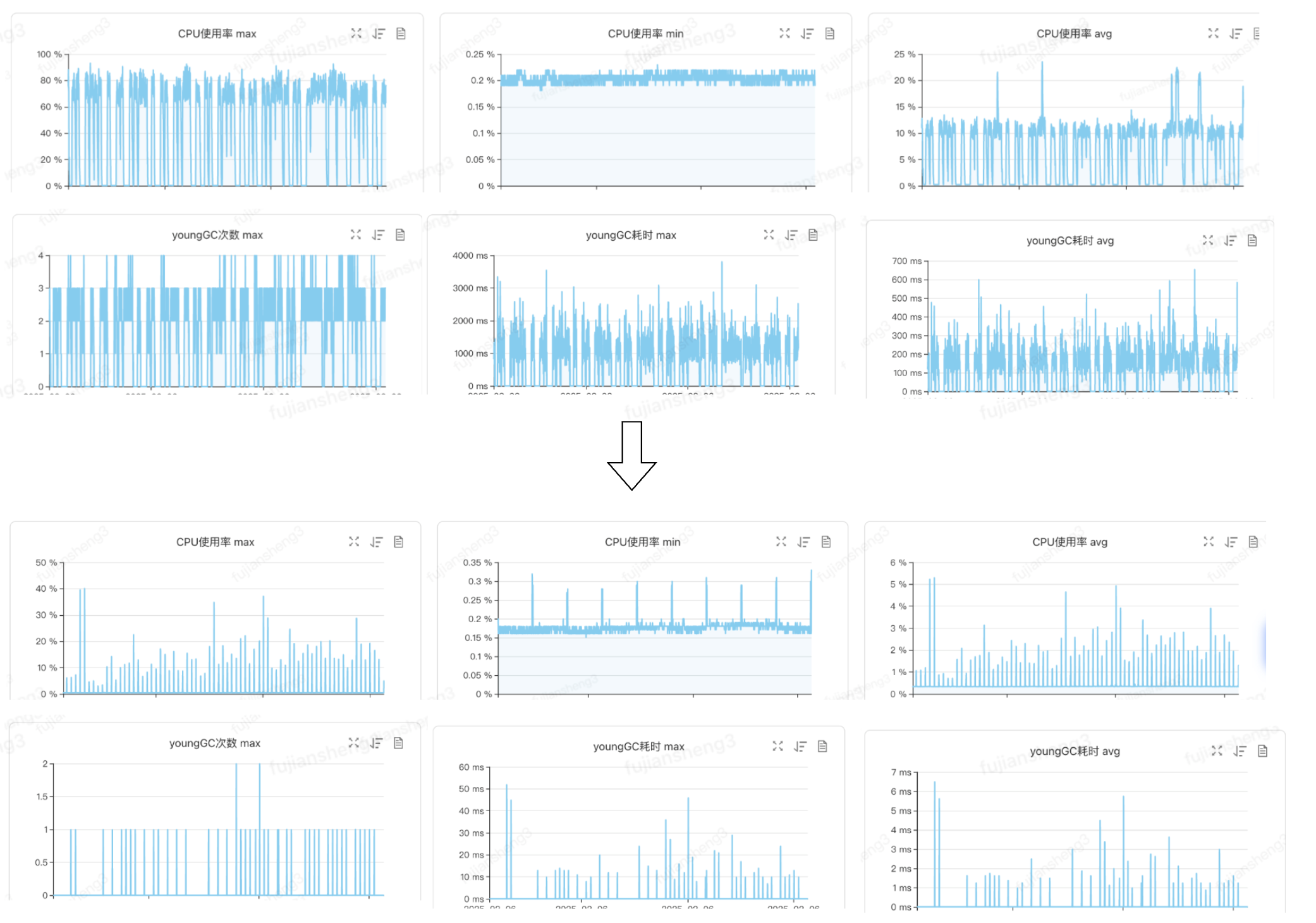
券促全量出仓时效性优化
随着业务发展券促数据量越来越大(优惠券千万级,绑定sku总量百亿规模,单券最大绑定sku6亿),全量出仓耗时越来越长而且极易失败。
券促出仓执行耗时越来越长,而且高频统计查询极易失败从而导致任务失败,券促出仓需要统计券促绑定sku数量用于区分大小券并用于分片及分策略执行绑定sku出仓,但统计后返回数据耗时较长而且容易失败
优化策略
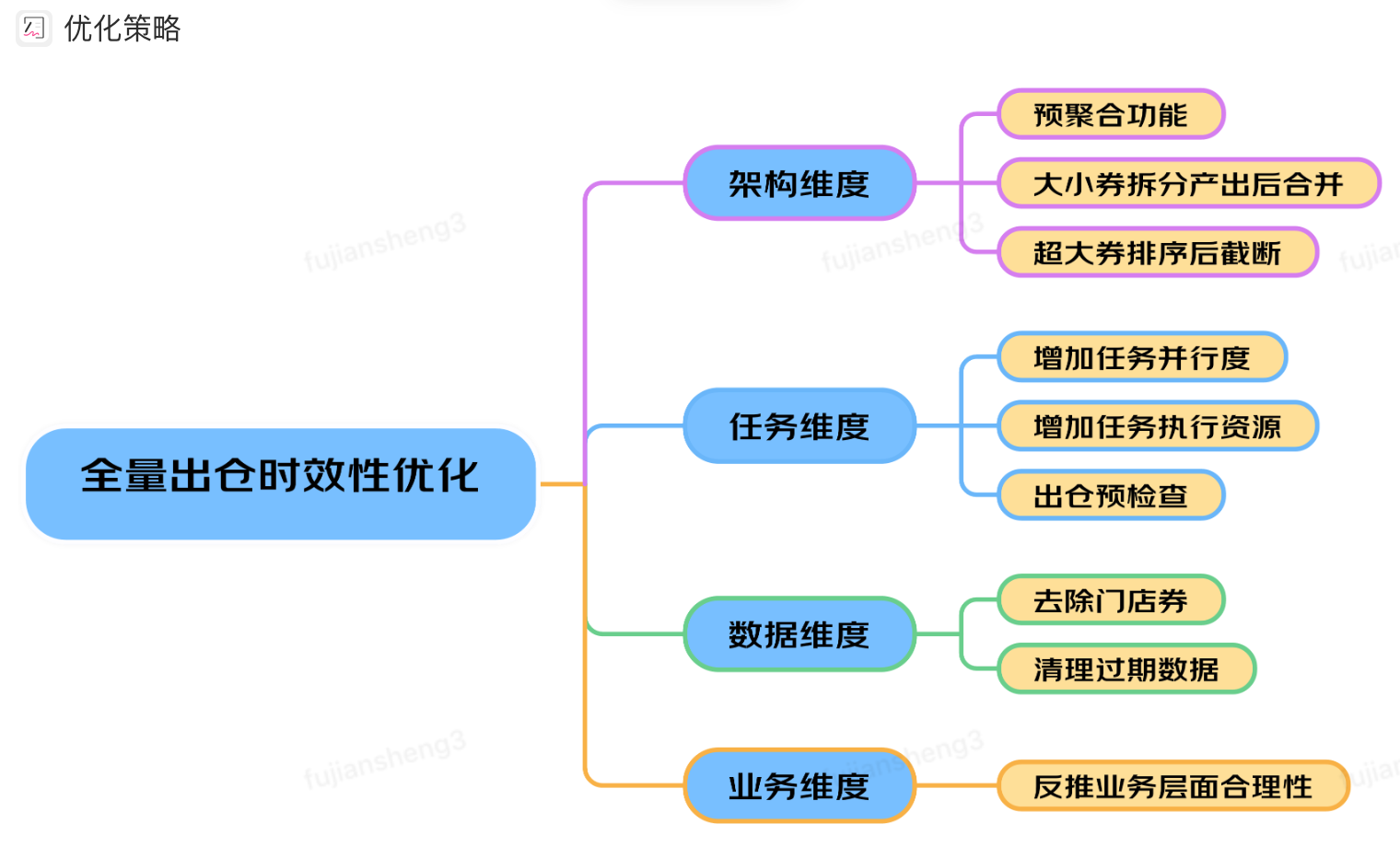
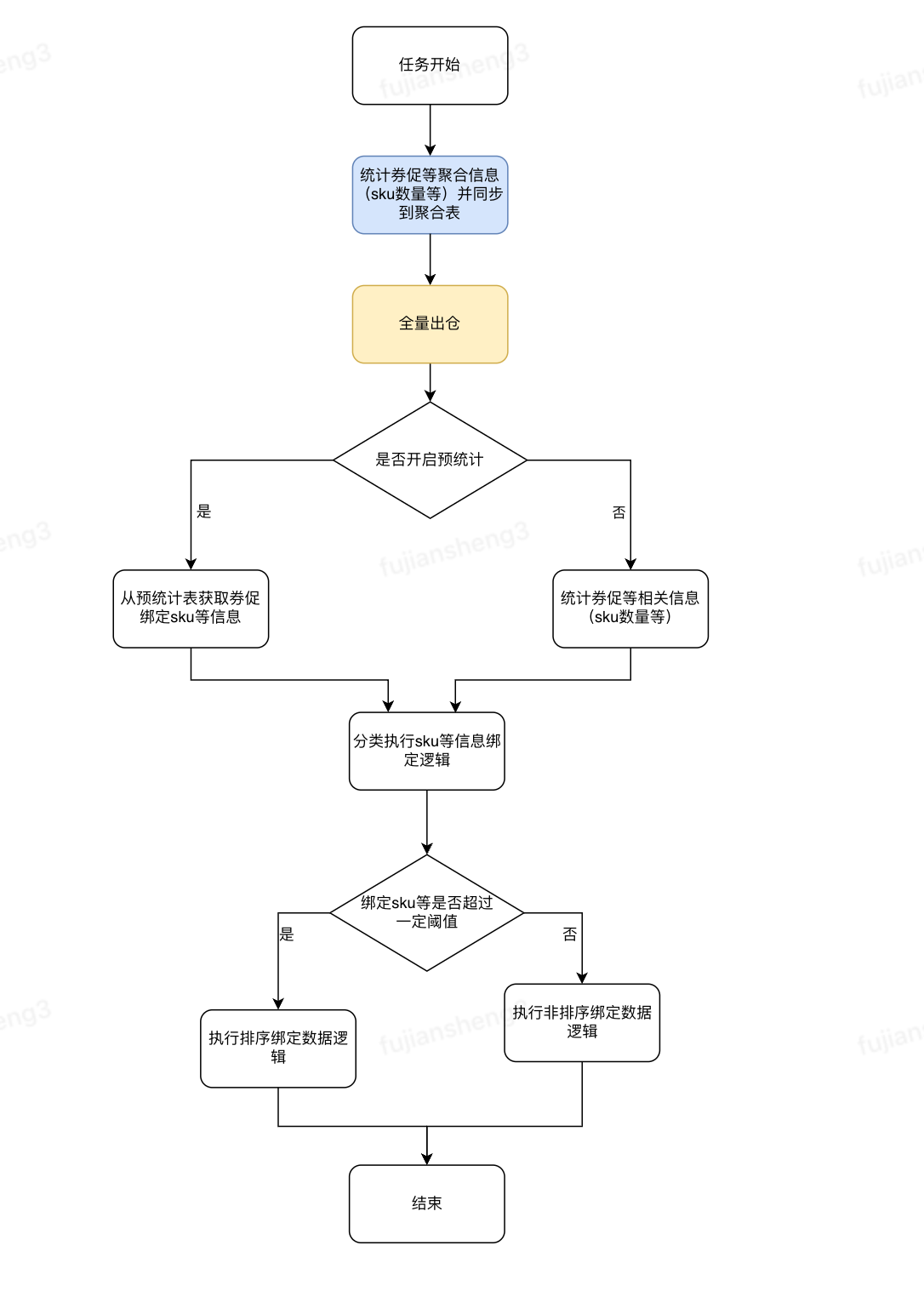
基于预统计的全量出仓方案
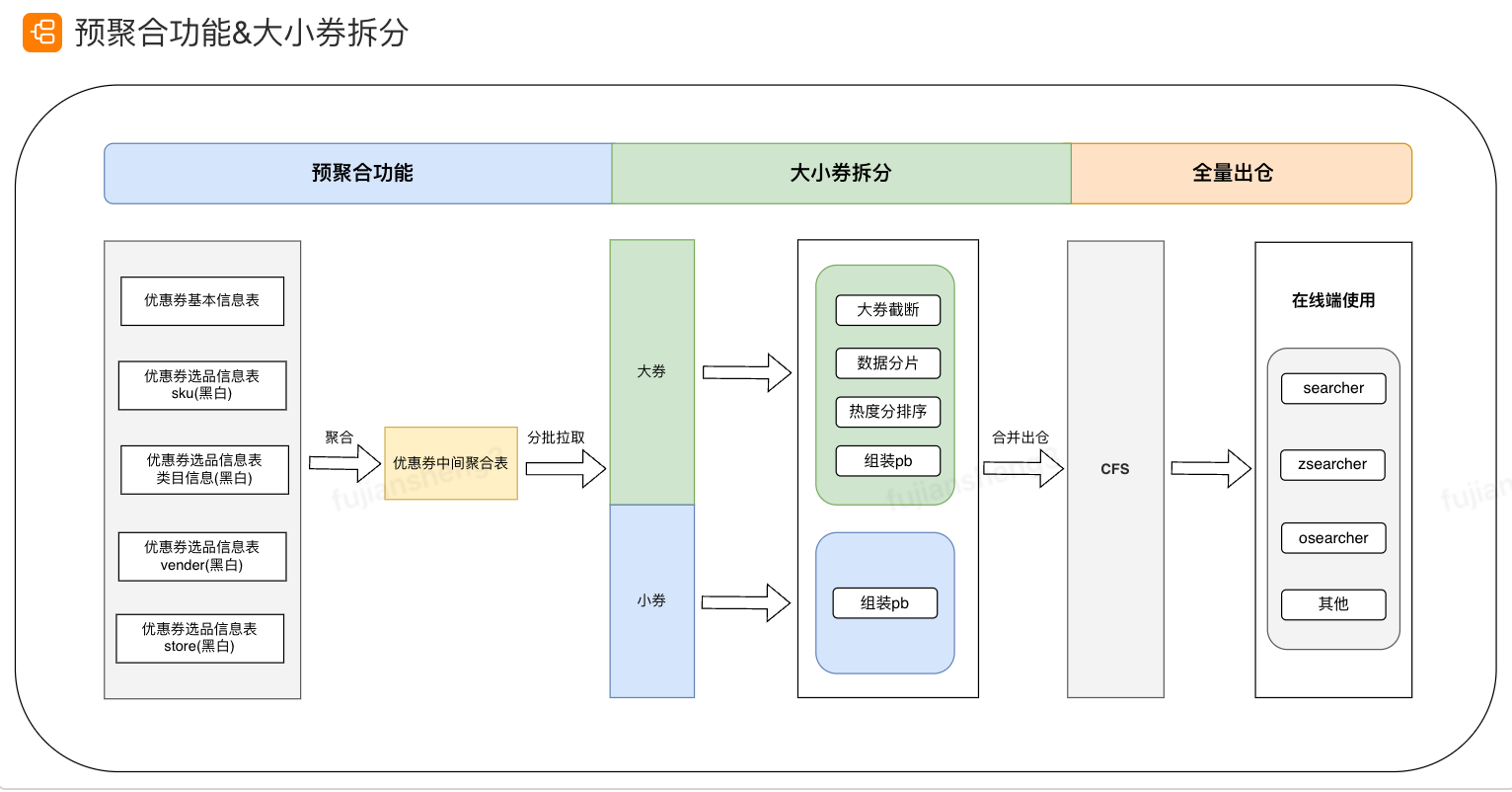
预聚合功能&大小券拆分
收益
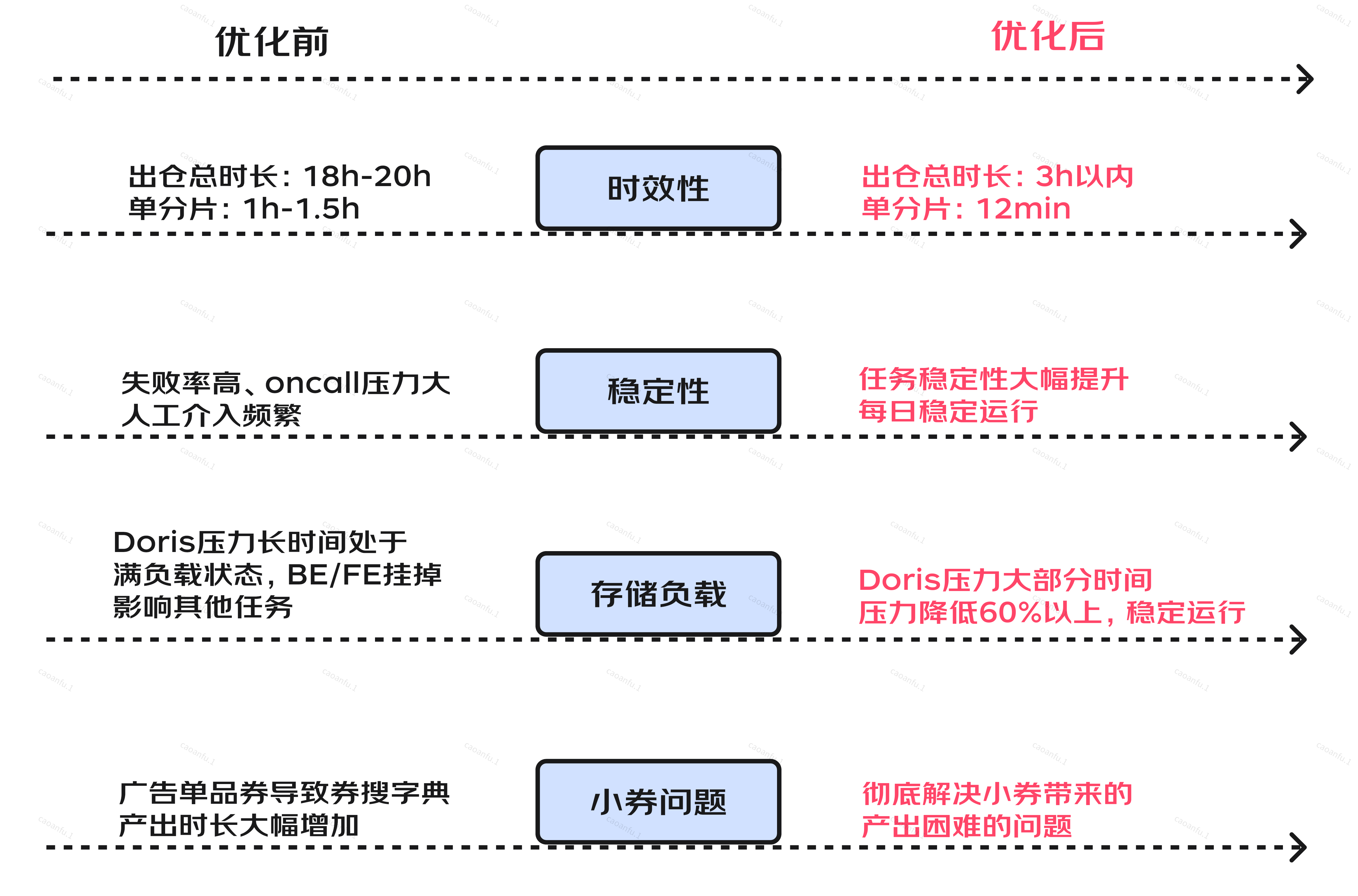
1.优惠券新版方案上线
优惠券searcher白单分片耗时从平均1h降低到20min,大小从11G降低到2G;
优惠券zseacher白单分片耗时从平均1h降低到15min,大小从11G降低到2G;
在线端降低内存存储降低10%。
2.osearcher去除storeList 等方案上线
本地盘存储单分片14G降低到几百M。单分片执行耗时从1h降低到5min;
在线端内存降低14%启动时间大幅降低;
在线端稳定性提升不再有cpu消耗毛刺。
3.时效性:优惠券searcher、zsearcher单分片耗时从平均1h降低至12min,券搜字典出仓任务耗时由20h降低至3h以内,产出时效提升85%以上。
4.存储:底层存储Doris CPU负载平均降低60%以上,内存使用率降低50%以上,查询量降低90%以上。
5.稳定性:券搜字典产出稳定性大幅提升,降低人工干预成本。
6.解决问题:从数据架构层面彻底解决小券带来的券搜字典计算、产出困难的问题。
名词解释
JIMDB:JIMDB是一款基于Redis研发的,具备高性能、高可用、在线伸缩能力的分布式缓存服务
DORIS:Doris 是一款基于 MPP 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景
总结
通过对券搜数据架构的演进与优化,我们已经完成“搜推优惠券数据架构”全链路系统化建设:彻底解决券促数据出仓滞后与时效瓶颈,实现百亿级券促数据场景下的分钟级更新,同时将计算与存储资源消耗降低90%以上。同时将方案沉淀为行业级可复用实践方案(包含多篇文章及专利成果)并已在主站、垂站、外卖等多场景落地。
未来,我们将继续致力于AI赋能的自动化运维系统、paas化平台、数据核对等提升服务质量及数据质量方面的建设,进一步提升系统的可用性和稳定性,以满足业务快速发展的需求,推动技术与业务的深度融合。





