



近年来,CPS联盟业务一路迅猛发展,流量呈爆发式增长,流量系统峰值已突破 10 万 /s 的大关,订单量实时计算能力更是实现了分钟级达到几百万以上的飞跃,轻松实现海量订单实时零延迟的佣金计算,流量系统支持了可以根据业务横向扩容,刚好25年618马上开战,在这里简单总结一下联盟这几年的备战保障思路及方法,供大家参考交流
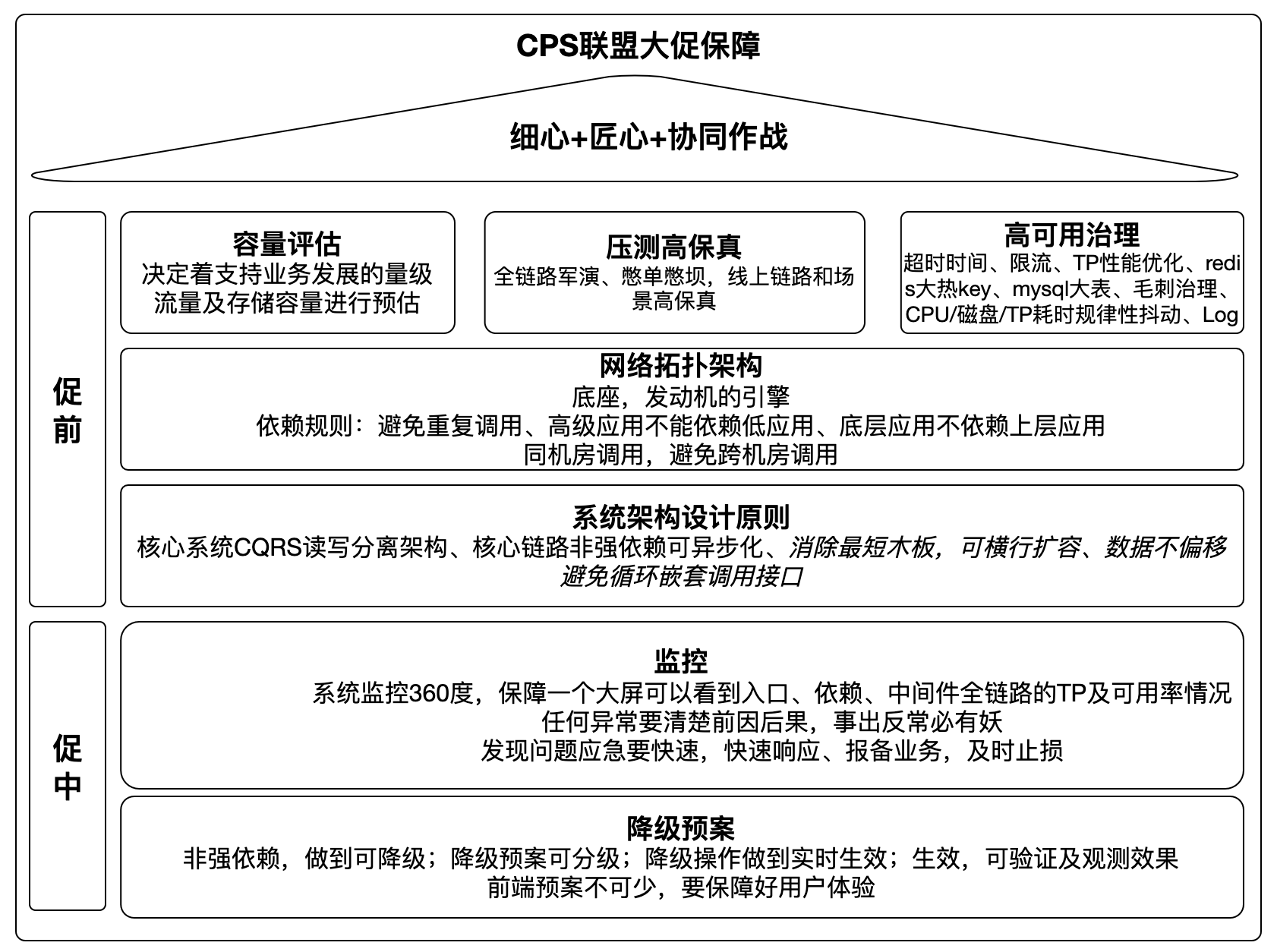
在大促备战的关键时期,我们每个人需要对所负责的核心系统运行状态十分了解,这要求我们对多个关键领域进行细致入微的梳理,做到心中有数,这些关键领域涵盖高保真压测、容量预估、高可用治理、应用网络拓扑结构、系统架构、监控、降级预案及其演练。
一、容量预估:为系统“粮草”精打细算
容量预估不仅仅是对流量预估的简单预测,对于诸如 jimdb、mysql、ck、es 等数据存储组件而言,依据业务数据的增长轨迹,精准规划存储容量同样刻不容缓。以 jimdb 为例,部分场景下它承担着业务流量请求缓存的重任,此时我们就需要综合考量流量大小以及KEY缓存空间的占用情况,科学合理地评估其容量需求。只有提前为系统的 “粮草” 做好充足且精准的准备,才能确保在大促的 “枪林弹雨” 中,数据存储系统能够稳如磐石,避免因容量不足而导致的 “粮草危机”,保障数据的可靠存储与高效调用。
二、高可用治理:严守 “八大注意” 构建稳固防线
高可用治理犹如构建一座坚固的堡垒,“八大注意事项” 则是这座堡垒的基石,当然这些更应该在常态化治理好,大促更多做check。其中毛刺治理、规律性抖动、log往往容易忽略,需要重点关注。
1、超时及限流配置,合理设置超时时间,像jimdb、mysql、依赖的RPC接口,时间太长,容易拖死服务,时间太短,超时严重,需要根据调用量及性能要求,设置超时时间,比如我们对jimdb往往在100ms、高性能的接口也在100ms以内。精准的限流配置则如同为系统安装了一个 “安全阀”,避免瞬间高流量的 “洪水猛兽” 冲垮系统,确保系统始终在安全、稳定的轨道上运行。
2、TP 性能优化,密切关注 TP99、TP999 等关键性能指标,它们如同系统的 “健康指标”,反映着系统的响应速度和处理能力,我们一般要求对外提供的接口TP99在200ms以内。
3、redis 大热 key 排查,redis 中的大热 key 就像隐藏在系统中的 “定时炸弹”,随时可能引发缓存雪崩,对系统造成致命打击,因此,必须将其列为重点排查对象。
4、mysql 大表处理,mysql 大表常常是影响系统性能的 “绊脚石”,庞大的数据量可能导致查询效率低下,我们的订单单表往往都会在500万以内。
5、慢SQL排查,慢 SQL 如同系统中的 “慢性疾病”,虽不致命,但长期积累会严重影响系统的 “健康”。通过细致的排查和优化,及时发现并治愈这些 “疾病”,能有效提升数据库的性能。
6、毛刺治理,对于 TP999 及 Max 峰值出现的毛刺现象,特别是那些明显异常的长耗时情况,比如超过 2 秒甚至 10 秒的 “超长待机”,我们务必秉持 “事出反常必有妖” 的严谨态度,深入挖掘其背后的 “妖魔鬼怪”。这些异常毛刺可能是系统深层次问题的 “冰山一角”,如果在大促前未能及时解决,很可能在高压力环境下引发 “蝴蝶效应”,导致系统全面崩溃。
7、规律性抖动分析,当 CPU、磁盘繁忙程度以及 TP99 指标出现规律性抖动时,这就如同系统发出的 “求救信号”,往往暗示着系统存在潜在异常。例如定时 JOB 归档数据、计算效果数据等操作,都可能是抖动的 “始作俑者”。面对此类情况,我们需要进行全面细致的评估,判断是否需要对相关操作进行优化。若暂时不进行优化,也必须提前制定完善的 “应急预案”,以防问题在大促期间集中爆发,对业务造成严重冲击。
8、log 排查,日志是系统运行的 “黑匣子”,记录着系统的一举一动,但是频繁打印log,尤其是同步打印log,也会严重影响性能,在以往的坑中也层遇到过,在多年以前佣金规则tp99要求10ms以内的rpc接口,因为增加了一条log,影响选品调用规则生成选品索引,影响了选品更新,通常一个请求打印一次log影响不大,并且尽量异步打印;另外针对error频繁,也要认真排查,error肯定是哪儿有问题的,我们能够从中发现许多隐藏在系统深处的问题线索,助力我们在大促前提前发现并解决潜在风险。
三、网络拓扑架构:梳理系统 “脉络” 数据高效稳定流转
网络拓扑架构就像是系统的 “脉络”,贯穿于各个系统之间,影响着数据的流转与交互。每次大促前,网络拓扑架构是我必定会逐一对每个系统进行细致剖析的关键环节。在这个过程中,系统调用不合理的情况屡见不鲜,比如底层应用直接调用 BFF(Backend for Frontend)层服务,或者1级流量应用去调用 3级管理端应用。同时,数据流转途经哪些机房也不容忽视,我们必须对这些信息了如指掌。
我们遵循这样的原则,将网络拓扑架构视为发动机的引擎,严格依照以下依赖规则进行梳理与优化:
1、避免重复调用,杜绝无意义的重复操作,减少系统资源浪费,提升整体运行效率。
2、层级依赖规范,高级应用不应依赖低级应用,底层应用也不应依赖上层应用,以此保证系统架构的清晰与稳定,避免因不合理的依赖关系导致的潜在风险。
3、机房调用优化,优先采用同机房调用,尽可能避免跨机房调用,从而降低网络延迟,提高数据传输速度与稳定性。
四、系统架构设计:打好系统稳定的“地基”
在过往作为架构师负责系统的过程中,每到大促时期,都会对小组内的系统进行一次全面梳理,实际上,这种系统全量梳理工作最好能常态化开展,提前识别潜在问题。然而,这一点常常容易被大家忽视。回顾以往出现的问题,架构设计不合理的情况时有发生,进而引发诸如数据库雪崩、服务宕机等严重后果。例如在数据存储方面,分库分表时可能出现数据偏移问题;又如在使用 Flink 计算引擎时,如果大量数据集中在集群的某一个节点进行计算,极有可能导致集群崩溃。
因此,在架构设计阶段,我们务必关注这些要点,并依据以下原则对系统进行梳理,进而提出优化方案:
1、核心系统采用CQRS读写分离架构,通过这种架构模式,将数据的读取和写入操作分离,提高系统的并发处理能力与性能。读操作和写操作可以根据各自的特点进行优化,减少读写之间的相互影响,确保系统在高并发场景下能够稳定高效运行。比如联盟京享红包、奖励系统,从去年统一升级为读写分离的CQRS的架构,流量洪峰已经不是问题,可以横行扩容。
2、核心链路遵循非必要依赖异步化/不依赖原则,对于核心链路中的各个环节,若非必要,尽量避免同步操作以及过度依赖。这样可以降低系统间的耦合度,当某个环节出现问题时,不至于影响整个核心链路的运行,提高系统的容错性和稳定性。
3、消除最短木板,实现横向扩容,如同木桶的盛水量取决于最短的木板,系统的性能也往往受限于性能最差的组件或环节。我们要找出并解决这些瓶颈问题,同时设计系统架构时要便于横向扩容,即在不改变系统整体架构的前提下,通过增加相同类型的组件或节点来提升系统的处理能力,以应对不断增长的业务需求。
4、确保数据不偏移,在数据存储和处理过程中,尤其是涉及分库分表等操作时,要采取有效措施保证数据分布均匀,避免数据偏移。数据偏移可能导致某些节点负载过重,而其他节点资源闲置,严重影响系统的整体性能和稳定性。
5、避免循环嵌套调用接口,在构建在线服务时,应极力规避在循环嵌套结构中调用接口或执行 SQL 操作,此类操作不仅会显著增加系统的资源消耗,还可能导致性能瓶颈。
五、监控:构建360无死角监控大屏
对于监控工作而言,全链路360监控的可视化至关重要,应将其整合于一张大屏之上,实现系统运行状态的全景式呈现。只需一眼,便能迅速定位问题所在,洞察系统全貌,从流量入口的起始点,到各依赖服务的交互环节,再到中间件的运行状况,全方位展示全链路的关键性能指标(如 TP99、TP999 等)以及可用率,让系统健康状况清晰可辨。
同时,面对任何异常情况,需秉持 “事出反常必有妖” 的理念,探寻其背后的根源。每一个细微的异常波动,都可能是系统潜在问题的外在表现。唯有抽丝剥茧、追根溯源,才能从根本上解决问题。
六、降级预案:灵活降级 守护核心业务与用户体验
在大促等业务高峰时,系统承压,降级预案是保障系统稳定与用户体验的重要手段。关于降级预案,强调以下几点:
1、对于非强依赖,可降级,系统资源紧张时,能及时调整这些部分,保障核心业务。
2、预案可分级,构建分级的降级预案体系,依据业务场景、压力程度等因素,灵活选择适配的降级方案,精准应对不同情况。
3、降级操作需实时生效,一旦触发条件,系统迅速响应,避免资源过度消耗。
4、降级生效后,效果要可验证、可观测,建立监控机制,跟踪策略执行,确保既缓解系统压力,又减少对业务干扰。
5、前端预案用户体验必不可少,前端直接面向用户,降级时要优化展示与交互,减少用户感知异常,如友好提示、调整页面布局等,保障用户体验。
6、有损降级需同步,务必提前与业务部门同步,共同商讨应对,同时,及时公告用户,说明原因、影响及恢复时间,争取理解支持。
大促备战是一项复杂而系统的工程,需要我们对核心系统的各个方面进行深入了解、精心准备和持续优化。只有全方位做到心中有数,才能在大促这场没有硝烟的战争中,确保核心系统稳如泰山,为联盟业务的持续繁荣保驾护航。






