



背景
在日常开发中,不可避免的要用到分批查询或分页查询,其中的场景有很多,有的是WEB页面的分页查询效果,或移动端向下滑动的分页查询,有的则是因为目标数据量巨大,不得已而分批查询。无论是出于性能考虑,还是大报文考虑,抑或页面的效果,分批或分页查询都是研发的日常。
本文尝试,对日常项目用到的分批分页查询做一下方案的回顾和浅析。
查询场景及方案
一、普通分批分页查询场景
方案1 普通LIMIT OFFSET分页查询方式
通过数据库直接LIMIT OFFSET 的方式是最简单,也是最常用的分页查询方式。
SELECT
id,
warehouse_no,
location_no,
sku,
sku_level,
lot_no,
pack_code,
owner_no,
extend_content
FROM
st_stock
WHERE
deleted = 0
AND warehouse_no = '6_666'
ORDER BY
id ASC
LIMIT 100,10
该方法直接简单,开发和运维简单,可读性高,但当offset值(偏移量)非常大时,弊端也比较明显:深分页性能问题比较严重,例如 LIMIT 1000000, 10 。
当执行LIMIT 1000000, 10时,SQL的处理流程是:
扫描并读取前1,000,000条记录
丢弃这1,000,000条记录
返回接下来的10条记录
这意味着即使只需要10条数据,数据库也必须访问和处理大量的"无用"数据。
简言之,深分页,IO开销大:需要读取大量无用数据页;内存消耗高:大量数据加载到内存后被丢弃;CPU消耗高:排序、过滤操作消耗大量CPU资源。
方案2 基于子查询或二次查询的分页查询
SELECT
s.id,
warehouse_no,
location_no,
sku,
sku_level,
lot_no,
pack_code,
owner_no,
extend_content
FROM
st_stock s
JOIN
(
SELECT
id
FROM
st_stock
WHERE
deleted = 0
AND warehouse_no = '6_666'
ORDER BY
id ASC LIMIT 100,10
)
s2
ON
s.id = s2.id
或
SELECT
s.id,
s.warehouse_no,
s.location_no,
s.sku,
s.sku_level,
s.lot_no,
s.pack_code,
s.owner_no,
s.extend_content
FROM st_stock s
WHERE EXISTS (
SELECT 1
FROM (
SELECT id
FROM st_stock
WHERE deleted = 0
AND warehouse_no = '6_666'
ORDER BY id ASC
LIMIT 100,10
) AS s2
WHERE s.id = s2.id
);
除了直接在SQL中进行分页处理,还可以通过二次查询的方式来实现。
第一步,先分页查询id列表;
SELECT id
FROM st_stock
WHERE deleted = 0
AND warehouse_no = '6_666'
ORDER BY id ASC
LIMIT 100,10;
id字段有主键索引,避免回表。
第二步,以第一步的id列表作为in条件,查询库存信息。
SELECT
id,
warehouse_no,
location_no,
sku,
sku_level,
lot_no,
pack_code,
owner_no,
extend_content
FROM st_stock
WHERE id IN (id1, id2, id3, ...);
注意:下面的SQL方式是错误的,SQL语法不支持:
SELECT
id,
warehouse_no,
location_no,
sku,
sku_level,
lot_no,
pack_code,
owner_no,
extend_content
FROM
st_stock s
where id in
(
SELECT
id
FROM
st_stock
WHERE
deleted = 0
AND warehouse_no = '6_666'
ORDER BY
id ASC LIMIT 100,10
)
SQL 错误 [1235] [42000]: This version of SQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
解决方案就是使用上面的方式实现。
方案3 游标分页,滚动式查询
SELECT
id,
warehouse_no,
location_no,
sku,
sku_level,
lot_no,
pack_code,
owner_no,
extend_content
FROM
st_stock
WHERE
deleted = 0
AND warehouse_no = '6_666'
AND id > 100
ORDER BY
id ASC
LIMIT 10
与方案一相比,最大的区别是增加了id条件,本次id的条件是上一次查询结果集中的最大id,通过id滚动式查询,缩小检索范围。
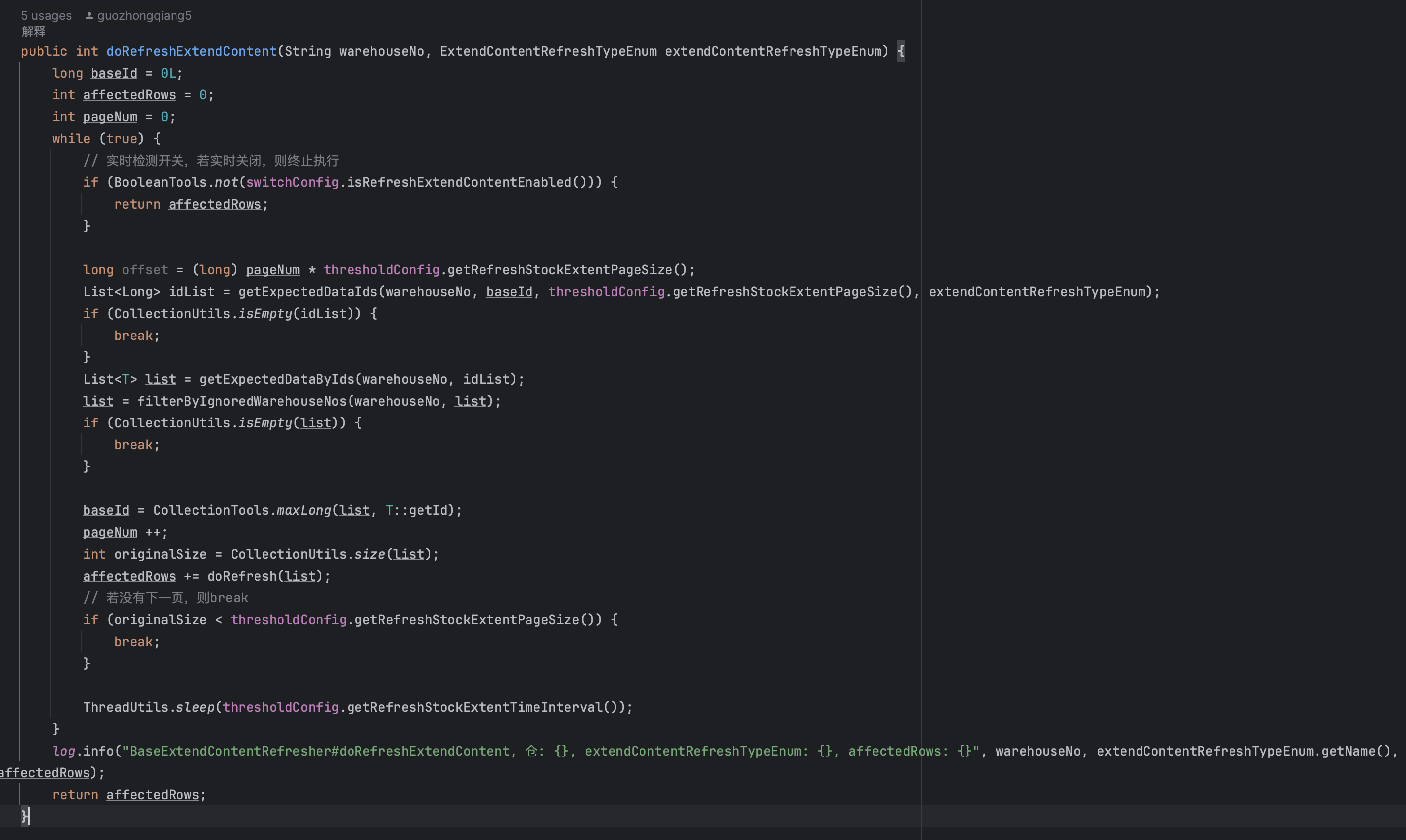
上图就是一个游标分页查询的案例。
二、动态数据分批分页导出查询场景
对于动态变化的数据,想要分批分页导出,而且想要保证数据的准确性,该如何处理呢?
方案1 对目标数据加锁
将导出条件对应的目标数据锁定,导出结束后再解锁这批数据。导出时间被锁定的数据行,不能update、delete,可以select。
| id | SKU | …… | locked |
|---|---|---|---|
| 2019609892142206976 | 123 | …… | 1 |
| 2019695225349345280 | 456 | …… | 1 |
| 2019326832070885376 | 789 | …… | 1 |
| 2027414057350348800 | 110 | …… | 0 |
| 2027414069316685824 | 118 | …… | 0 |
优势
- 可以保持在导出期间稳定导出数据,减少因为数据的动态变化影响数据的准确性。
- 如果在导出期间,符合条件的数据库行有新增(insert),在数据库主键ID递增的情况下,新增行的id更大,排序在后,可以正常导出这部分新增数据,不受影响。
劣势
- 锁定的这部分导出数据,在导出期间,只读,不能执行写服务,相当于停产导出,适合于生产低谷时段或停产时段进行导出。
方案2 生成导出数据快照
将导出条件对应的目标数据生成导出库存快照数据,导出执行是将本次版本的快照数据导出,导出数据快照过时可以清理。
实时数据
| id | SKU | …… |
|---|---|---|
| 2019609892142206976 | 123 | …… |
| 2019695225349345280 | 456 | …… |
| 2019326832070885376 | 789 | …… |
| 2027414057350348800 | 110 | …… |
| 2027414069316685824 | 118 | …… |
快照数据
| id | SKU | …… |
|---|---|---|
| 2019609892142206976 | 123 | …… |
| 2019695225349345280 | 456 | …… |
| 2019326832070885376 | 789 | …… |
优势
- 在数据导出期间稳定导出数据,每次导出的数据都有单独的导出数据快照版本,导出期间数据的准确性得到保障。
- 在数据导出期间,即使有数据的变化,也不影响导出效果。不锁数据行,不影响生成生产作业。
劣势
- 如果在导出期间,符合条件的数据库行有新增(insert),这部分数据即使符合导出条件,也不会导出,因为这部分新增的数据在导出数据快照之后生成,并未在快照数据中。
- 需要生成导出数据快照,导出数据快照版本需要单独的库表存储,同时也会占用磁盘资源。
- 导出数据快照生成期间,倘若符合条件的数据行有变化,需要对快照数据生成特殊处理,比如一次性生成快照等方式。
三、内存分页查询场景
在日常研发过程中遇到的分页查询,大部分都可以借助SQL数据库、ES等存储中间件自身的分页功能实现,但个别场景下并不符合,比如数据并未存储在SQL数据库或ES中,而是内存计算出来的一种结果数据;或者数据库中存储的数据维度并不符合,并不能通过简单的GROUP BY等方式实现维度加工;或者数据库中存储的数据,需要通过第三方RPC远程接口实时获取特殊属性打标过滤后,才可以作为目标数据使用。
在这些场景下,我们会用到内存分页的方式处理。
内存分页方案
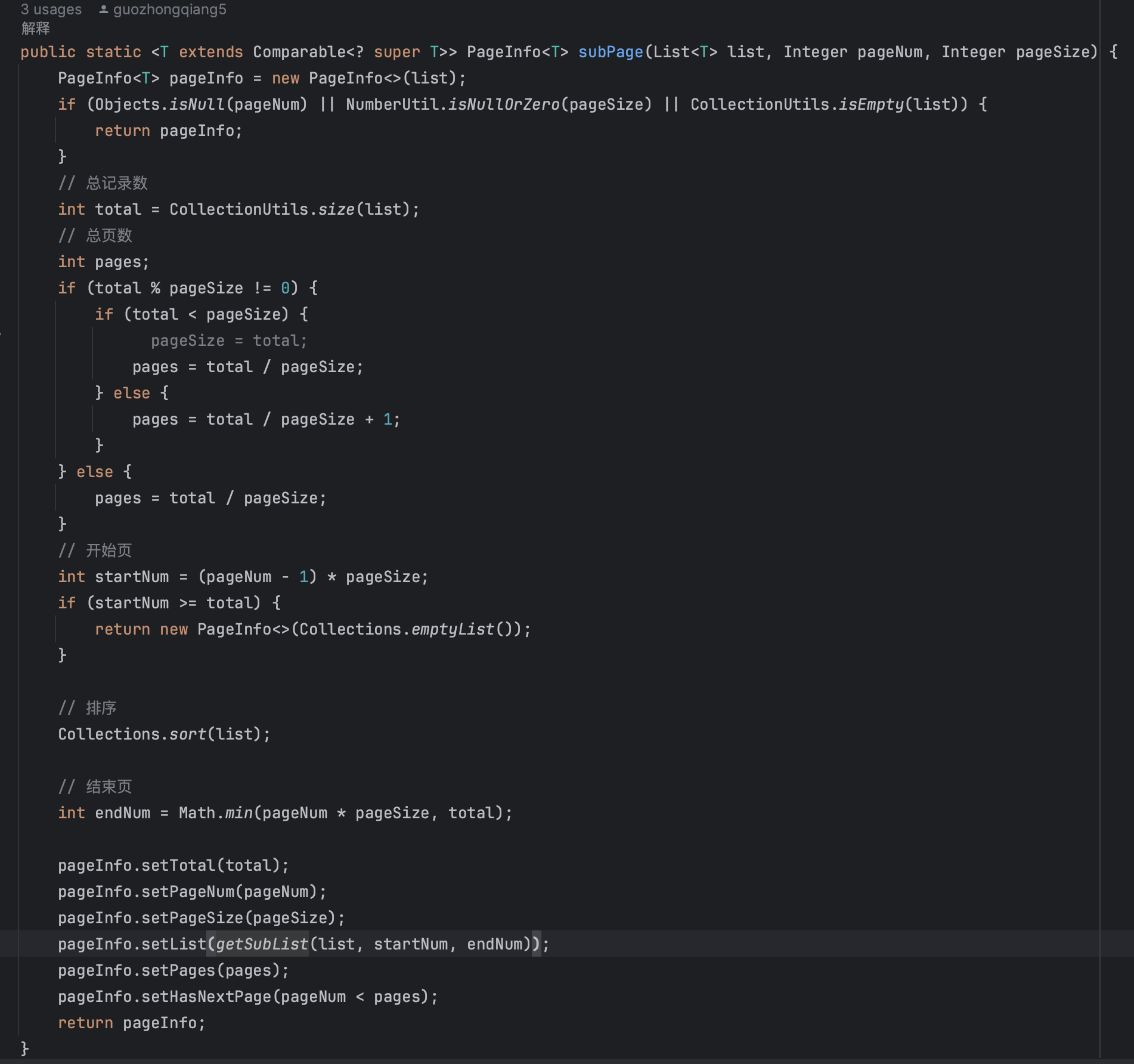
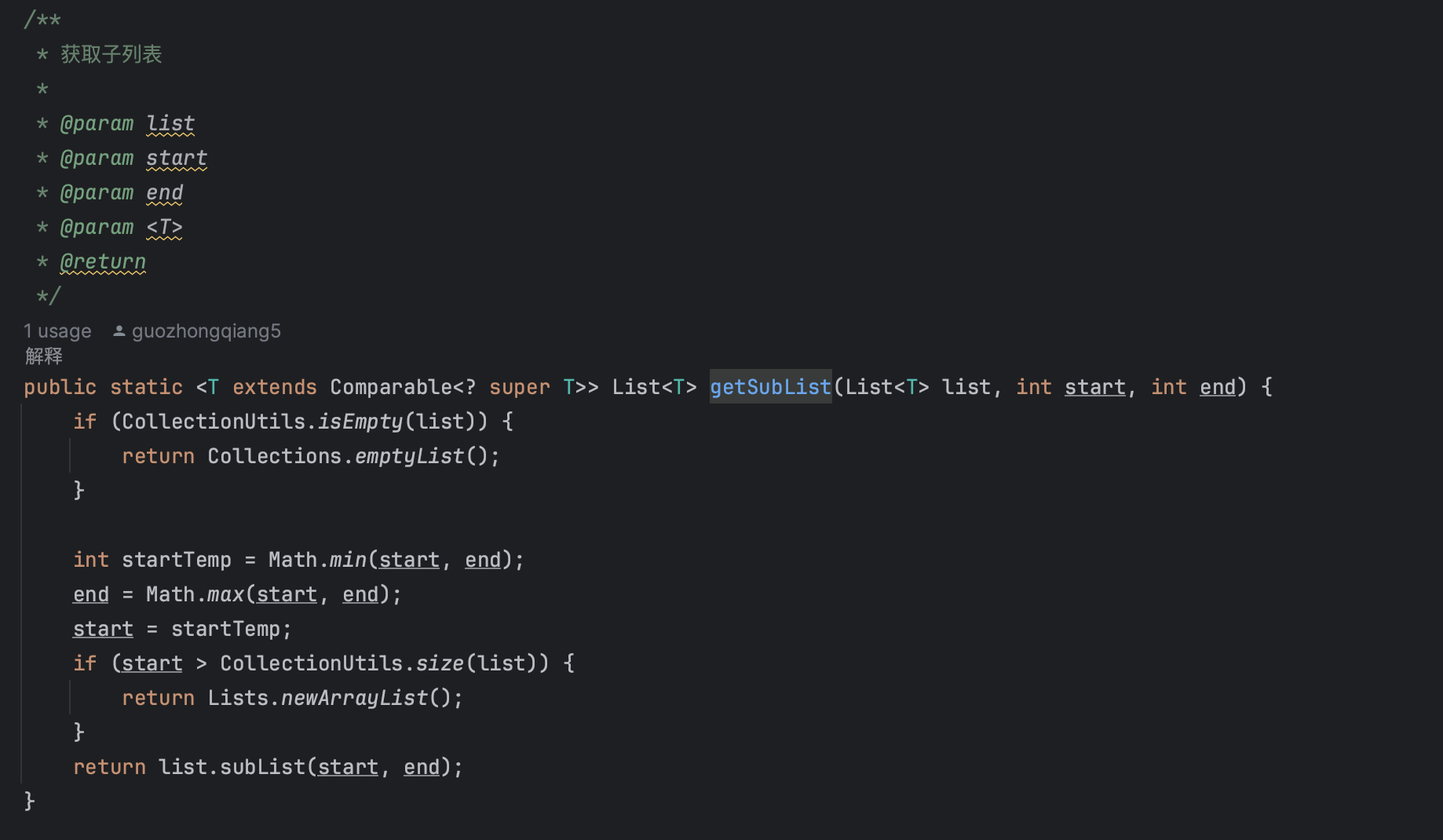
上面的示例,是一个简单的内存分页处理方式。
总结
本文回顾了日常研发过程中,经常遇到的普通分批分页查询场景、动态数据分批分页导出查询场景、内存分页查询等场景,探讨了对应的解决方案。方案并非固定一成不变的,也有各自的利弊和局限性,在合适场景下,选择合适的方案即可。






