您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
工作中对InheritableThreadLocal使用的思考
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
工作中对InheritableThreadLocal使用的思考
wy****
2024-12-25
IP归属:北京
642浏览
代码评审时,发现在线程池中使用InheritableThreadLocal上下文会使其中的线程变量失效,无法获取到预期的变量值,所以对问题进行了复盘和总结。 ## 1. 先说结论 `InheritableThreadLocal` 只有在父线程**创建**子线程时,在子线程中才能获取到父线程中的线程变量;当配合线程池使用时:**“第一次在线程池中开启线程,能在子线程中获取到父线程的线程变量,而当该子线程开启之后,发生线程复用,该子线程仍然保留的是之前开启它的父线程的线程变量,而无法获取当前父线程中新的线程变量”**,所以会发生获取线程变量错误的情况。 ## 2. 实验例子 - 创建一个线程数固定为1的线程池,先在main线程中存入`变量1`,并使用线程池开启新的线程打印输出线程变量,之后更改main线程的线程变量为`变量2`,再使用线程池中线程(发生线程复用)打印输出线程变量,对比两次输出的值是否不同 ```java /** * 测试线程池下InheritableThreadLocal线程变量失效的场景 */ public class TestInheritableThreadLocal { private static final InheritableThreadLocal<String> threadLocal = new InheritableThreadLocal<>(); // 固定大小的线程池,保证线程复用 private static final ExecutorService executorService = Executors.newFixedThreadPool(1); public static void main(String[] args) { threadLocal.set("main线程 变量1"); // 正常取到 main线程 变量1 executorService.execute(() -> System.out.println(threadLocal.get())); threadLocal.set("main线程 变量2"); // 线程复用再取还是 main线程 变量1 executorService.execute(() -> System.out.println(threadLocal.get())); } } ``` > 输出结果: </p> > main线程 变量1 </p> main线程 变量1 发现两次输出结果值相同,证明发生线程复用时,**子线程获取父线程变量失效** ## 3. 详解 ### 3.1 JavaDoc > This class extends ThreadLocal to provide inheritance of values from parent thread to child thread: when a child thread is created, the child receives initial values for all inheritable thread-local variables for which the parent has values. Normally the child's values will be identical to the parent's; however, the child's value can be made an arbitrary function of the parent's by overriding the childValue method in this class. Inheritable thread-local variables are used in preference to ordinary thread-local variables when the per-thread-attribute being maintained in the variable (e.g., User ID, Transaction ID) must be automatically transmitted to any child threads that are created. > `InheritableThreadLocal` 继承了 `ThreadLocal`, 以能够让子线程能够从父线程中继承线程变量: 当一个子线程`被创建`时,它会接收到父线程中所有可继承的变量。通常情况下,子线程和父线程中的线程变量是完全相同的,但是可以通过重写 `childValue` 方法来使父子线程中的值不同。</p> 当线程中维护的变量如UserId, TransactionId 等必须自动传递到**新创建的任何子线程**时,使用`InheritableThreadLocal`要优于`ThreadLocal` ### 3.2 源码 ```java public class InheritableThreadLocal<T> extends ThreadLocal<T> { /** * 当子线程被创建时,通过该方法来初始化子线程中线程变量的值, * 这个方法在父线程中被调用,并且在子线程开启之前。 * * 通过重写这个方法可以改变从父线程中继承过来的值。 * * @param parentValue the parent thread's value * @return the child thread's initial value */ protected T childValue(T parentValue) { return parentValue; } ThreadLocalMap getMap(Thread t) { return t.inheritableThreadLocals; } void createMap(Thread t, T firstValue) { t.inheritableThreadLocals = new ThreadLocalMap(this, firstValue); } } ``` 其中`childValue`方法来获取父线程中的线程变量的值,也可通过重写这个方法来将获取到的线程变量的值进行修改。 在`getMap`方法和`createMap`方法中,可以发现`inheritableThreadLocals`变量,它是 `ThreadLocalMap`,在`Thread类`中  #### 3.2.1 childValue方法 1. 开启新线程时,会调用Thread的构造方法 ```java public Thread(ThreadGroup group, String name) { init(group, null, name, 0); } ``` 2. 沿着构造方法向下,找到`init`方法的最终实现,其中有如下逻辑:**为当前线程创建线程变量以继承父线程中的线程变量** ```java /** * @param inheritThreadLocals 为ture,代表是为 包含可继承的线程变量 的线程进行初始化 */ private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc, boolean inheritThreadLocals) { ... if (inheritThreadLocals && parent.inheritableThreadLocals != null) // 注意这里创建子线程的线程变量 this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); ... } ``` 3. `ThreadLocal.createInheritedMap(parent.inheritableThreadLocals)`创建子线程 `InheritedMap` 的具体实现 `createInheritedMap` 方法,最终会调用到 `ThreadLocalMap` 的**私有构造方法**,传入的参数parentMap即为**父线程中保存的线程变量** ```java private ThreadLocalMap(ThreadLocalMap parentMap) { Entry[] parentTable = parentMap.table; int len = parentTable.length; setThreshold(len); table = new Entry[len]; for (int j = 0; j < len; j++) { Entry e = parentTable[j]; if (e != null) { @SuppressWarnings("unchecked") ThreadLocal<Object> key = (ThreadLocal<Object>) e.get(); if (key != null) { // 注意!!! 这里调用了childValue方法 Object value = key.childValue(e.value); Entry c = new Entry(key, value); int h = key.threadLocalHashCode & (len - 1); while (table[h] != null) h = nextIndex(h, len); table[h] = c; size++; } } } } ``` 这个方法会对父线程中的线程变量做**拷贝**,其中调用了`childValue`方法来获取/初始化子线程中的值,并保存到子线程中 - 由上可见,可继承的线程变量**只是**在线程**被创建的时候**进行了初始化工作,这也就能解释为什么在线程池中发生线程复用时不能获取到父线程线程变量的原因 ## 4. 实验例子流程图 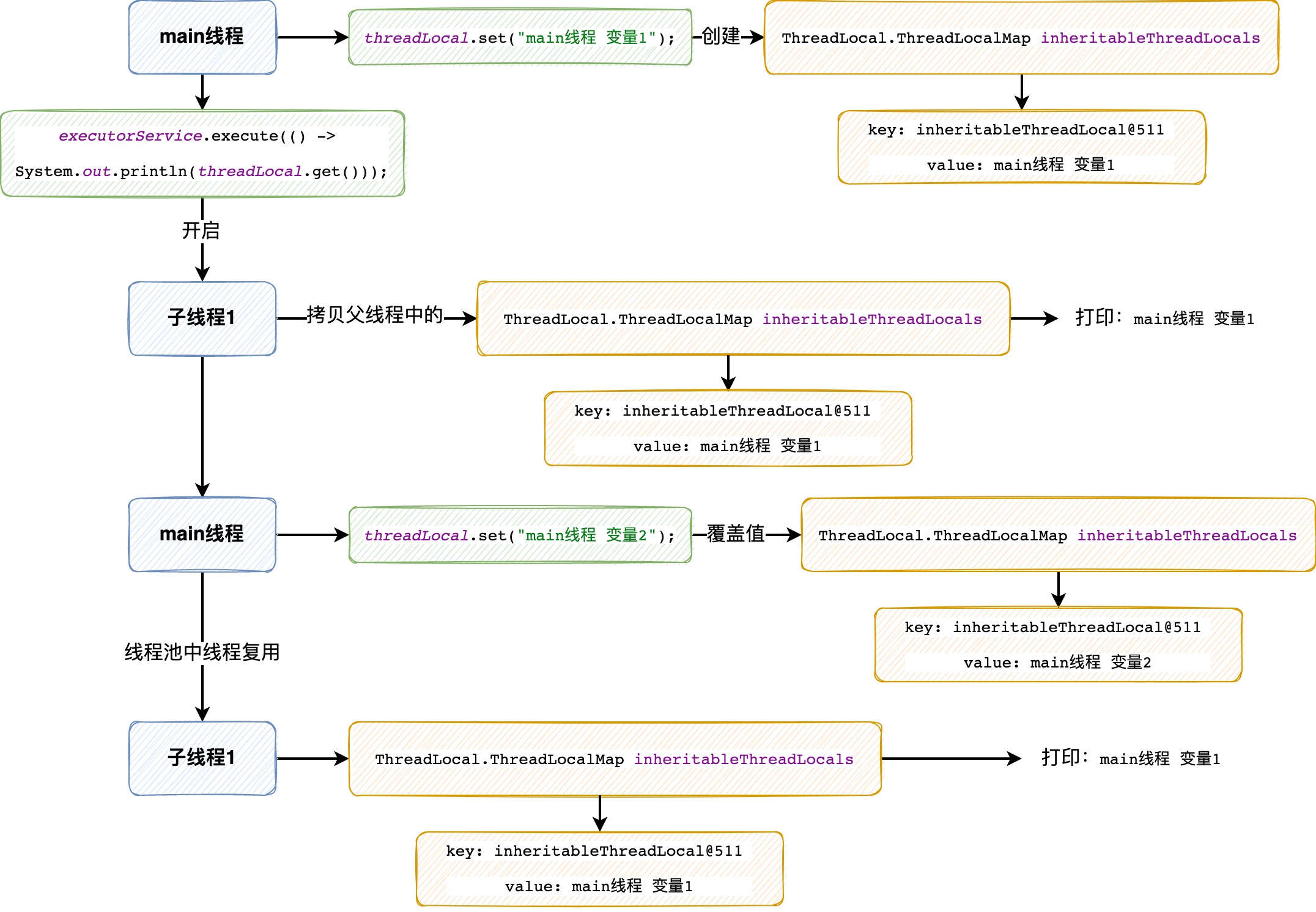 1. main线程`set main线程 变量1`时,会调用到`InheritableThreadLocal`的 `createMap`方法,创建 `inheritableThreadLocals` 并保存线程变量 2. 开启子线程1时,会拷贝父线程中的线程变量到子线程中,如图示 3. main线程`set main线程 变量2`,会覆盖主线程中之前set的mian线程变量1 4. 最后发生线程复用,子线程1无法获取到main线程新set的值,仍然打印 main线程 变量1 ## 5. 解决方案: TransmittableThreadLocal 使用阿里巴巴 `TransmittableThreadLocal` 能解决**线程变量线程封闭**的问题,测试用例如下,在线程池提交任务时调用`TtlRunnable`的`get`方法来完成线程变量传递 ```java public class TestInheritableThreadLocal { private static final TransmittableThreadLocal<String> threadLocal = new TransmittableThreadLocal<>(); // 固定大小的线程池,保证线程复用 private static final ExecutorService executorService = Executors.newFixedThreadPool(1); public static void main(String[] args) { threadLocal.set("main线程 变量1"); // 正常取到 main线程 变量1 executorService.execute(() -> System.out.println(threadLocal.get())); threadLocal.set("main线程 变量2"); // 使用TransmittableThreadLocal解决问题 executorService.execute(TtlRunnable.get(() -> System.out.println(threadLocal.get()))); executorService.shutdown(); } } ``` > 输出结果: main线程 变量1 main线程 变量2 - 注意:对象类型需要注意线程安全问题 - 具体用法参考 https://github.com/alibaba/transmittable-thread-local --- **That's all.**
上一篇:纯配时效服务-双Redis集群设计
下一篇:探讨篇(三):代码复用的智慧 - 提升架构的效率与可维护性
wy****
文章数
47
阅读量
38527
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
38527
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-12-25
2024-12-25 642浏览
642浏览






