



1. 改造的背景
1.1 geomesa-hbase本身存在的问题
Geomesa在向Hbase写入数据时,是通过HTable和Put对象来实现的。在写入的时候,需要指定列族名、列名和Cell的value值,而这些指定的内容都需要经过序列化才能进入到Hbase当中。
在原生的GeoMesa当中,value值是将整个feature的所有信息都封装在一起,统一进行序列化的。虽然这样能够让存储的空间更小,避免了查询多个字段的问题,但是这样的方式使得查询没有针对性,在进行查询时,一些价值不大的信息也会被查询到,极大地占用了资源。
1.2 预期目标
希望能够通过一些源码级别的修改,找到GeoMesa与Hbase进行交互的位置,将插入过程从单列写入改造成为多列写入,将整个的feature信息存储由存储为一个列转变为分属性存储在不同的列中。以此来提升查询的针对性和效率。
2. 过程分析
在GeoMesa当中,主要负责插入数据是org.locationtech.geomesa.hbase.index.HBaseIndexAdapter类当中的createInsert方法,在这个方法当中,GeoMesa创建了Put对象,一个Put对象对应一个行键,这个行键是已经经过时空索引处理过后的二进制数组。
- override protected def createInsert(row: Array[Byte], feature: HBaseFeature): Mutation = {
- val put = new Put(row)
- feature.values.foreach(v => put.addImmutable(v.cf, v.cq, v.value))
- feature.visibility.foreach(put.setCellVisibility)
- put.setDurability(HBaseIndexAdapter.durability)
- }
然后这个put对象设定了若干个value,但是在默认情况下,这个feature对象中的value只有一个对象,就是整个feature当中的所有信息。而具体设定这些信息的则是通过org.locationtech.geomesa.hbase.data.HBaseFeature当中的values值来设定的。
- lazy val values: Seq[RowValue] = serializers.map { case (colFamily, serializer) =>
- new RowValue(colFamily, HBaseColumnGroups.default, serializer.serialize(feature))
- }
从上面的代码可以看出,values的类型是封装了若干个RowValue对象的序列,而在其内部设定时依然是单个RowValue对象,也就是说,values封装的是serializers遍历之后的所有RowValue对象。
在创建RowValue对象时,其中设定列名的是第二个参数,默认情况下是HBaseColumnGroups.default,这个参数存在于org.locationtech.geomesa.hbase.index.HBaseColumnGroups类当中,默认情况下是“d”。也就是说默认情况下,写入的数据只有一个列,列名为“d”。
override val default: Array[Byte] = Bytes.toBytes("d") 3. 改造方法
3.1 切入点
由上述分析可以看出,主要可以修改的点有三处:
首先,可以修改HBaseColumnGroups类当中的default参数,这样的话就可以修改列名。但是这样的修改方式只是将列名修改过来了,虽然在Hbase当中会显示新的列名,但是本质上依然是整个feature进行序列化,整个存储的过程。而且这样的修改方式也会连带地修改列族名,由修改过的实验可以看出,在进行写入操作时,列族名也会调用这个default参数。
其次还可以修改HBaseIndexAdapter类当中的createInsert方法,在进行feature.values的遍历时,可以进行拆分。但是这种方式仍然是在RowValue封装好以后才进行遍历的,本质上value值已经被序列化了,再进行拆分已经没有价值了。
最好的方案是修改HBaseFeature类当中的values,因为RowValue是在这个函数内生成的,因此可以进行一些更为细致的操作。
3.2 修改过程
首先需要在values函数当中,判断feature里面的属性存储情况,以便抽取不同的数据,将这些数据分成不同的RowValue进行封装,存储。
- lazy val values: Seq[RowValue] = serializers.flatMap { case (colFamily, serializer) =>
- // Fid
- println(feature.getAttribute(0))
- // Date
- println(feature.getAttribute(1))
- // Geometry
- println(feature.getAttribute(2))
- // Description
- println(feature.getAttribute(3))
执行修改后的程序,可以看到这些属性成功被取出来了。

接下来就是将这些数据封装在不同的RowValue对象当中。修改如下:
- lazy val values: Seq[RowValue] = serializers.flatMap { case (colFamily, serializer) =>
- Seq(
- new RowValue(colFamily, Bytes.toBytes("Fid"), Bytes.toBytes(feature.getAttribute(0).toString)),
- new RowValue(colFamily, Bytes.toBytes("Date"), Bytes.toBytes(feature.getAttribute(1).toString)),
- new RowValue(colFamily, Bytes.toBytes("Geometry"), Bytes.toBytes(feature.getAttribute(2).toString)),
- new RowValue(colFamily, Bytes.toBytes("Description"), Bytes.toBytes(feature.getAttribute(3).toString)))
- }
3.3 运行结果
在默认情况下,value当中将feature的所有数据都放在了一起,呈现出来的就是只有一列。

而经过修改以后,不同属性的数据都已经被放在了不同的列当中。
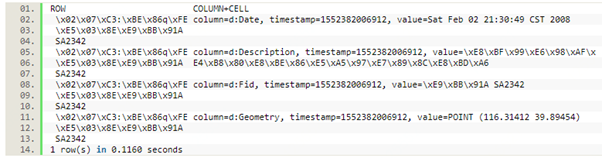
4. 存在的问题
最大的问题就是这样的修改可能会导致数据无法通过原有GeoMesa来进行查询的问题,因为原有GeoMesa依然是通过列族名“d”和列名“d”来进行查询的。
还有一个问题就是和原有序列化机制可能会出现冲突的问题。因为如果写入的序列化机制和读取的序列化机制产生冲突,就会报版本错误的问题。






